
You're Renting a Supercar to do the School Run


TL;DR
- Most revenue work is the school run: bounded, repeated, mechanical. You've been handed a frontier reasoning model for it and pointed at the meter.
- Frontier vendors are tightening the screws on purpose. The best models now land outside your flat subscription, behind metered credits at a premium. The default is rigged toward the most expensive option, because the meter is the business model.
- A model tuned to revenue work does the bounded jobs better than a generalist. Cheaper is a side effect of fit, not the pitch.
- Keep the frontier model for the one call that earns it. Route everything else to a purpose-built tier. That's the whole optimization.
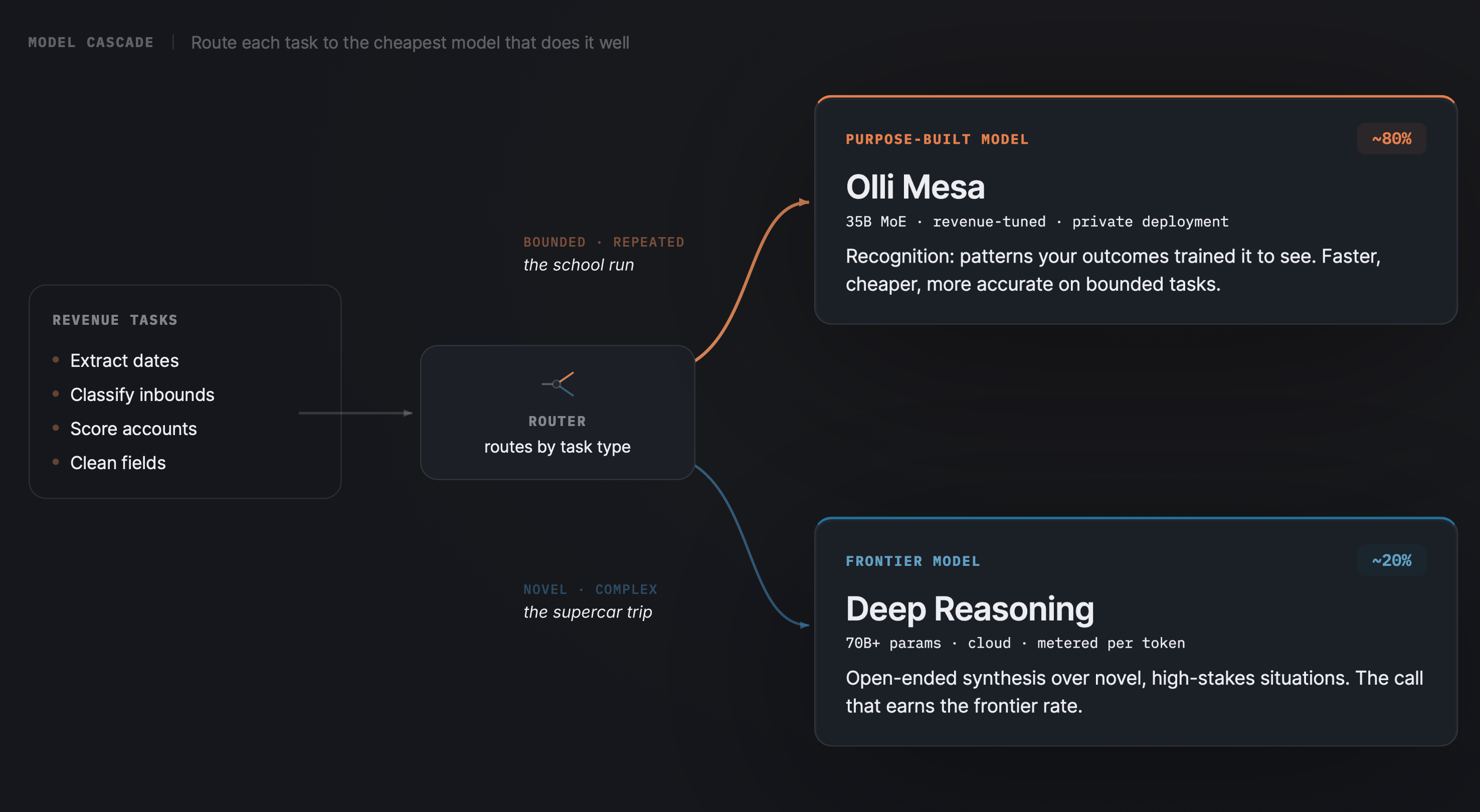
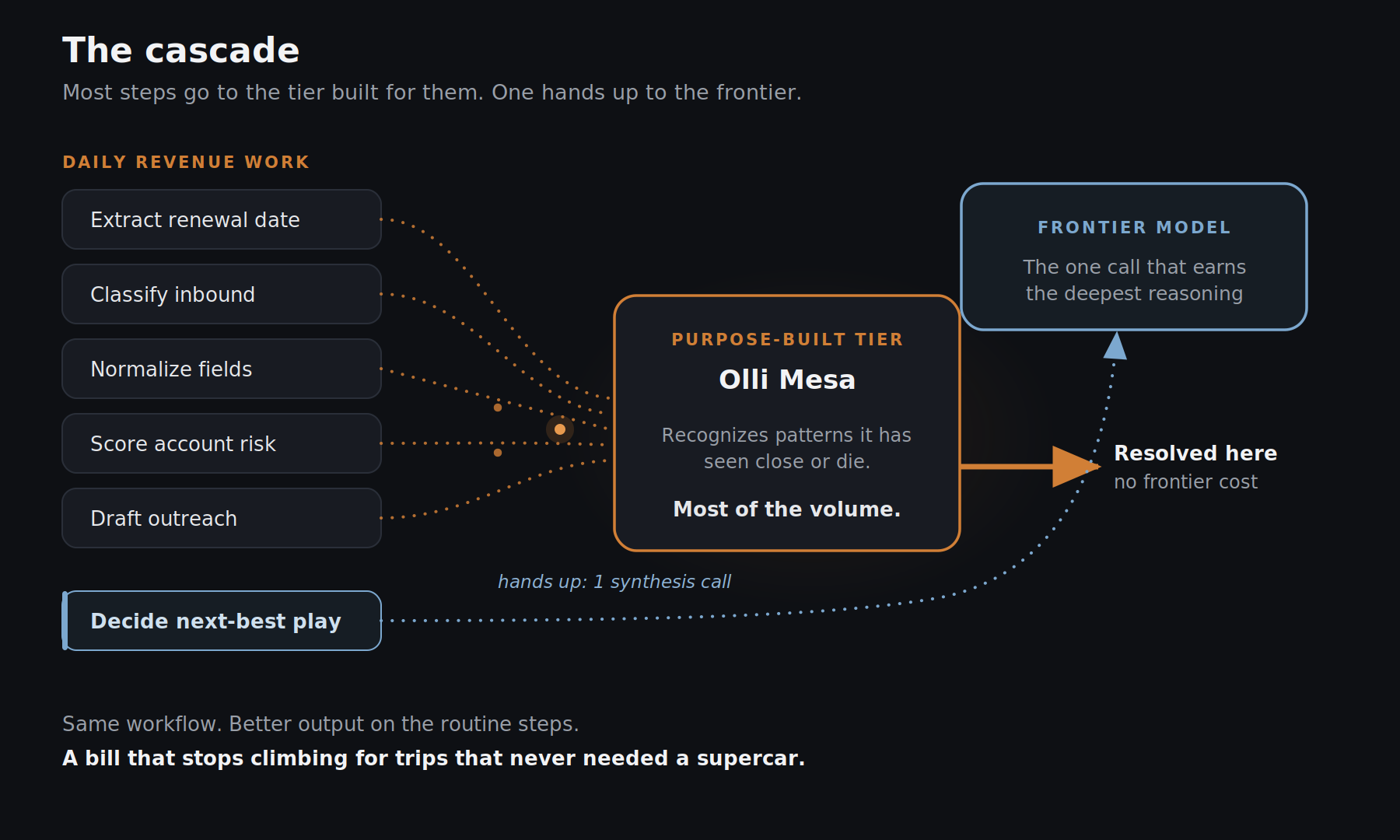
- Ours is Olli Mesa, the private model inside our Revenue Engineering Platform (REP): revenue-tuned out of the box, trained on your outcomes, and it never leaves your boundary.
The school run is most of your day
A supercar is the wrong car for the school run. Not just expensive. Worse at the job. Too much power you can't use, a fuel bill you feel every trip, built for a route you never drive. You'd never buy one to take the kids to school and pick up the groceries. And yet that's exactly the car the AI vendors have handed every revenue team, with the keys to nothing else.
Most of what a RevOps stack does all day is the school run:
- Pulling a renewal date out of a call transcript.
- Sorting an inbound into expansion or churn.
- Cleaning a title field.
- Scoring an account for risk.
- Picking which branch of a play to run.
None of that needs the most powerful model ever shipped. It needs a model that's good at that, cheap enough to run a thousand times a day without a Slack from finance. That gap, frontier rates for school-run work, is what AI cost optimization for revenue operations is actually about.
The meter is the business model
The strongest models are drifting out of the flat subscription and into metered credits. New releases don't land in the bucket you already pay for; they land behind usage-based pricing at a premium. Fable shipped at double the last flagship. The pattern is deliberate: train you to reach for the metered supercar by default, for everything, because the meter is where the margin is.
So the real problem was never "you can't afford the best model."
It's that you're being upsold into metered frontier usage for tasks a purpose-built model does better and cheaper, and the vendor is paid to keep you there.
The dealership makes its money on the gas. Fine for the dealership. Terrible for a revenue team running the same handful of jobs over and over across a whole book of business.
And the meter runs quietly. The AI invoice is the line nobody questions until it's too big to ignore, climbing in the background while the team is busy hitting pipeline. A lot of revenue leaders can already feel the throttle coming: the month the bill finally gets flagged, and someone asks what all of it was actually for. The honest answer, most of the time, is the school run.
A generalist is worse at revenue work, not just pricier
This is the non-obvious part.
The instinct is to frame the problem as cost alone. "The frontier model is too expensive for routine work." True, but incomplete. A frontier model is also worse at most revenue tasks than a smaller model built for them. Here's why.
A frontier model has read a million things and none of them are your pipeline. It's never seen your deal cycles, your closed-won, your closed-lost, or the specific shape of how accounts slip in your motion. Ask it a revenue question and it reasons from a generic prior over a raw CRM dump. It lands a passable answer and bills you the supercar rate to get there.
A model built for the job starts somewhere else entirely. It already knows what a slipping deal looks like in your world, because that's what it was trained on. It doesn't reason from scratch to a generic answer. It recognizes a pattern it has seen close, or seen die, hundreds of times.
That distinction (recognition vs. reasoning) is a way to think about the framework:
- Recognition tasks have a known pattern and one right answer. A model that has seen the pattern before is faster, cheaper, and more accurate than a model reasoning its way there from first principles. Most revenue work lives here.
- Reasoning tasks require open-ended synthesis over novel situations. No prior pattern to match. That's where the frontier model earns its rate.
We learned this the hard way:
When we first started routing tasks to a smaller model, we expected a tradeoff: worse accuracy, lower cost, acceptable. But that's not what happened.
On extraction and classification tasks, the smaller model was more accurate. Not by a little. It was returning the right answer in cases where the frontier model was confidently hallucinating a plausible-but-wrong one. The frontier model had never seen a renewal clause formatted the way our customers format renewal clauses. Ours had seen thousands of them. It wasn't even thinking about it. Just pattern-matching the way a radiologist reads a scan they've read a thousand times before.
The weird part was the latency. You could actually see the frontier model working harder on the tasks it was worst at, burning through a long chain of reasoning to arrive at the answer our model returned in a fraction of the time. Longer inference time, higher cost, worse answer. The trifecta nobody warns you about.
On bounded, repeated revenue work, the purpose-built model isn't the economy option. It's the better one, because the job is narrow and the supercar was built wide. The lower cost is a side effect of that fit, not a compromise for it.
One more thing RevOps teams miss:
Accuracy degrades under the wrong model, but silently. A frontier model reasoning from a generic prior won't throw an error on a misclassified inbound. It'll return a confident wrong answer, and you won't catch it until the pipeline review. We spent two weeks once chasing a phantom spike in "expansion" inbounds before we realized the frontier model was misreading a specific complaint pattern as an upsell signal. It had never seen that pattern before, so it guessed. Confidently. A recognition model trained on your actual outcomes catches what the generalist has never seen. The failure mode is different: the generalist fails quietly, the specialist fails loudly (or not at all).
Which trips actually need the supercar
Be honest about the limit, or the argument breaks. Some calls genuinely need the frontier model: the one where you take the whole worked-out state of an account and decide the next best play, where a wrong answer misroutes a rep's week. That call earns the most powerful model you can put on it. The mistake isn't using the supercar. It's using it for the groceries too.
So the answer was never "fire the frontier model." It's "stop reaching for it by reflex." A model cascade routes each step to the cheapest model that can do it well, and escalates only when the work demands it. Here's how the common RevOps tasks sort:
The shape to notice: the frontier model handles the rare, high-stakes synthesis. Everything bounded, repeated, and mechanical (most of the miles) goes to the tier built for it.
Right-sizing the model is one half of AI cost optimization for revenue operations. The other half is upstream, in the context itself: a model that rebuilds the whole account from scratch on every call runs up the bill no matter how well you've routed the work. The companion piece, How to cut AI agent costs: a context-engineering playbook for RevOps, covers that side. Together they account for both lines on the invoice: the context you keep reprocessing, and the model you pay to read it.
How to spot the school run in your own stack
You can run this audit on your own usage this week:
- Pull your highest-volume AI tasks. Sort by call count, not by how interesting the task is. The school run hides in the boring, frequent jobs.
- Tag each one: bounded or open-ended? Bounded means one right answer and a pattern that repeats (extract, classify, score, normalize). Open-ended means genuine synthesis where a wrong answer is expensive. Most of your volume will be bounded.
- Check what's billing. Every bounded, high-volume task running on a metered frontier model is supercar rates for the school run. That's your optimization list, ranked by volume × unit cost.
- Route, don't rip out. Move the bounded jobs to a purpose-built tier; leave the genuine synthesis on the frontier model.
Rule of thumb: if a task runs more than a few hundred times a day and has one right answer, it's the school run.
So we built the car for the route
That model is real, and it's ours: Olli Mesa, a core component of our Revenue Engineering Platform (REP).
It's deliberately not a giant: 35 billion parameters, mixture-of-experts, small enough to deploy privately and run cheaply at the volume a real stack demands. The value isn't the parameter count. It's what the model is built around. Three things make it the right car for the route:
- Revenue-tuned out of the box. It ships trained on a base revenue dataset, so a fresh deployment is good at revenue work on its first call, before it has seen one of your deals. Then it sharpens as your outcomes accumulate, personalizing to your pipeline, your motion, and your definition of a good deal.
- It runs inside your boundary. To use the metered supercar, you ship crown-jewel revenue data out to someone else's API to get billed on it. Olli Mesa deploys in your environment; your pipeline trains a model you run. For an enterprise that's a board-level decision, not a cost one, and the frontier vendors structurally can't follow you there.
- It learns from what actually closed. This is the engine. Loop, our context-engineering layer, materializes the worked-out state of every account and binds it to the outcome that followed: won, lost, slipped, saved. That outcome-labeled context does double duty: it's served to every agent so nothing rebuilds the account from scratch, and it's the training signal that makes the model yours.
Loop materializes the context, the outcomes label it, the model learns from it, and the model's judgments feed the context Loop serves next time. That's the flywheel, and it's the one thing a frontier vendor can't build, because it doesn't have your history of what closed and what died, and never will.
Why outcome-labeled data compounds
Most teams understand fine-tuning. Fewer teams think about what happens when the training data itself improves every cycle.
- Cycle 1: the model learns from your first batch of closed-won and closed-lost deals. It gets better at recognition tasks.
- Cycle 2: because it's better at recognition, it surfaces better context to the agents running on it. Better context means better rep decisions. Better rep decisions mean cleaner outcomes. Cleaner outcomes feed back as higher-quality training data. The model sharpens, the context improves, the outcomes get cleaner. Each cycle makes the next one better.
Here's the thing that still surprises us, even after building this:
Around the third cycle, the model starts catching patterns the team didn't know existed. We had a customer where the model started flagging deals as at-risk based on a combination of signals nobody had explicitly taught it to look for. Turned out there was a pattern in how procurement language shifted in the last two weeks of deals that eventually went dark.
The team hadn't codified that pattern because they'd never isolated it. The model had seen 400 examples of it and was just... recognizing it. That's not a feature you spec out. It's an emergent property of training on enough labeled outcomes in a narrow domain. It's also the kind of thing that makes you realize a frontier model reasoning from the open web was never going to find it, because the pattern only exists inside one company's deal history.
A frontier vendor can't enter this loop. It doesn't have your outcomes. It never will. That's not a feature gap. It's a structural one.
Frontier model vs. purpose-built: the honest comparison
The question to sit with
The frontier vendors will keep building more powerful models and keep moving them further behind the meter. Good business. Just not the road most of your revenue work drives.
So before the next renewal, the next credit pack, the next quiet line on the AI invoice: how much of what your stack did today was the school run, and how much of it did you pay supercar rates to do?
FAQ's on:
AI cost optimization for revenue operations
A model trained specifically on revenue data and tasks rather than the open internet, so it starts from patterns like closed-won, closed-lost, and slipped deals instead of a generic prior. On bounded jobs (extraction, classification, scoring), a specialized model can match or beat a much larger general model at lower cost and latency. Fluint builds this kind of model for revenue operations, where the same narrow tasks repeat thousands of times a day across a whole book of business.
A cascade routes each step to the cheapest model that can do it well. Mechanical and mid-tier work (pulling a renewal date, sorting an inbound, scoring an account) goes to a smaller specialized tier. Only steps that need the deepest reasoning, such as choosing the next play from a fully worked-out account, escalate to a frontier model. In a Fluint stack the private revenue model takes most steps and hands up selectively, so spend tracks the difficulty of the work.
A private deployment runs the model within your own boundary instead of sending data to a third-party API for billing. Your pipeline, your closed deals, and your account history stay inside your environment, and the model trains on them there. For regulated or enterprise buyers this is a governance decision as much as a cost one, a position the metered frontier vendors structurally cannot match. Exact setup depends on your existing infrastructure and data access.
Specialization pays back when a task is high-volume, narrow, and stable: the work that fills most of a revenue day. Fine-tuning and serving carry real dataset, evaluation, and monitoring costs, so the savings have to clear that bar. For repeated extraction, classification, scoring, and structured generation across a whole book of business, recurring inference savings usually outweigh those costs comfortably.
Yes, and it's usually the best setup. A mixed architecture lets a smaller specialized model handle routine, bounded steps while the frontier model is reserved for the one synthesis call that genuinely needs deep reasoning. Fluint runs its revenue model as the private tier inside a cascade, replacing the general-purpose small and mid models a team already pays for, and supplementing the frontier model only on the step that earns it. Nothing about it requires ripping out your frontier vendor.
Recognition means the model has seen the pattern before and identifies it. Reasoning means the model must synthesize an answer from scratch over novel inputs. Most revenue work (extraction, classification, scoring, normalization) is recognition. A purpose-built model trained on your outcomes does recognition faster, cheaper, and more accurately than a generalist reasoning from first principles. The frontier model earns its rate on the small number of genuinely novel, high-stakes synthesis calls.
Why stop now?
You’re on a roll. Keep reading related write-up’s:



Draft with one click, go from DIY, to done-with-you AI
Get an executive-ready business case in seconds, built with your buyer's words and our AI.
Meet the sellers simplifying complex deals
Loved by top performers from 500+ companies with over $250M in closed-won revenue, across 19,900 deals managed with Fluint

Now getting more call transcripts into the tool so I can do more of that 1-click goodness.



The buying team literally skipped entire steps in the decision process after seeing our champion lay out the value for them.


Which is what Fluint lets me do: enable my champions, by making it easy for them to sell what matters to them and impacts their role.

