
How to Cut AI Agent Costs: A Context Engineering Playbook for RevOps


TL;DR
- The token-price debate misses the point. A model can be cheap, or, like Fable, cost double the last one, but you do not set the per-token price and you do not control how many tokens a reasoning model burns thinking.
- The one big cost variable you do control is context: how much you feed an agent, and how many times. In a RevOps stack, every agent re-reads and re-reasons over the same deal on every call.
- This can be fixed. Work the account out once, store the result, serve it to every call, and reserve the expensive model for the one step that earns it.
- Done right it cuts agent spend by 30 to 70% on the same agents, which is the real shape of LLM token cost optimization.
How to Reduce AI Agent Costs: A Context Engineering Playbook for RevOps
When we first built the agent we called "Olli," he'd pull up a CRM account, run the data, and we'd read the result. Then we'd tweak one field and run it again. And again.
Every pass, he re-read the entire account and reasoned over it from scratch, even though almost nothing had changed since the last run. The bill climbed quietly until Nate flagged it, and I sat there staring at a run that had just reprocessed a full account to update a single number.
That was the moment: why are we reprocessing everything when the only thing that matters is what's different?
The token-price debate misses the point
Right now, the industry is arguing about the price of a token. Fable 5 shipped at double Opus 4.8. Reasoning models burn tokens you never see, one thinking step at a time. So everyone does per-token math.
That's the wrong fight.
Your AI bill is price × volume, and price is the half you don't control. The vendor sets it, the trend with frontier models is always up, and the strongest models are drifting from flat subscriptions into metered credits. You don't set the price of a token, and you don't get a vote on how many a model burns reasoning.
Volume is where it splits:
- Model-side volume: how many tokens the model burns reasoning, turn by turn, with no input from you.
- Context volume: how much you feed the agent and how many times you feed it. This is the largest piece of the bill, and the only part that's entirely yours.
The fastest way to reduce AI agent costs isn't negotiating a lower rate. It's engineering the context you send. And the single most expensive token in any workflow is the one you process twice.
Context explosion: the cost most teams don't see
If you run agents across your pipeline or existing customer base, you're likely reprocessing the same tokens over and over: a nightly risk assessment, a next-best-action agent, a CRM update. Same accounts, same context, same reasoning, billed again every time.
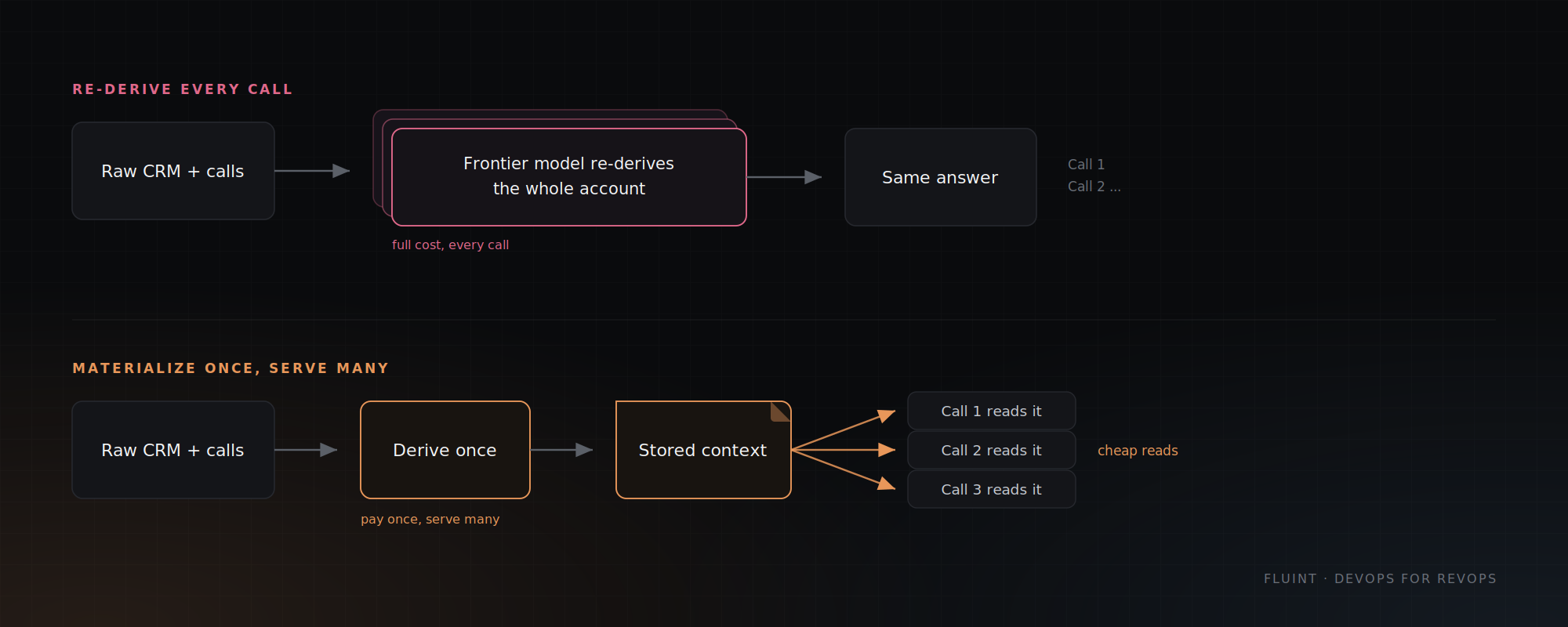
Context explosion is when an agent rebuilds the full state of a deal from raw CRM data on every call, instead of reading a result that was worked out once and stored.
This isn't a prompt problem. Trimming your system prompt saves a few lines. Re-reading the full state of an account, across every agent, every rep, and every nightly job, is where the budget goes.
How it shows up
Not in a dashboard. In a Slack message from finance: "Wait, we spent how much on AI this month?"
By spring 2026, FinOps Foundation director J.R. Storment was fielding calls from companies "3x over our entire 2026 token budget and it's only April." Glean CEO Arvind Jain put it flatly: the number-one topic for every enterprise right now is overblown AI budgets. The teams that signed all-you-can-eat AI subscriptions in early 2025 spent the first half of 2026 trying to trace where the money went.
Then the CRO asks the three questions that matter:
- Are we saving money?
- Are we making money?
- Can we prove it?
Most RevOps teams can answer none of them, because the spend isn't tied to the pipeline. You can see total usage. You can't see cost per account, cost per closed-won, or whether a run changed a field, advanced a stage, or just re-derived a risk score that was already right.
A usage dashboard shows you that an agent ran. It doesn't show you what the run was worth.
The fix: pre-materialize once, serve many
If you're an engineer, the principle is familiar. You don't recompile an entire project on every keystroke. You build once, cache the result, and rebuild only what changed. That's DevOps.
RevOps agents don't work this way yet. They rebuild the world from scratch on every run. The fix is a pipeline, not a cache, and it has three steps.
Step 1: Build the brief
Ingest the records, calls, and activity. Resolve them into a brief: one clean artifact representing the account's current state. This is structure, not judgment. You're turning a pile of scattered raw data into a single object the next step can read.
Step 2: Analyze the brief with purpose-built models
This is the step that matters, and it's not a generic LLM call.
You run purpose-built models over the brief, scoped to your pipeline and trained on your deal cycles, and write what they find back into it:
The key constraint: analysis runs on change, not on consumption. When something material lands (a new call, a pushed close date, a usage drop) the models rerun and update the brief. Between those events, nothing re-derives it. You pay for the analysis once per meaningful change and serve the result for free on every read in between.
Step 3: Serve the brief and route each step to the right model
Every downstream call now reads the brief instead of the raw pile. And because the brief is a small, pre-scored object, you unlock a second lever: model routing.
Most of a RevOps workflow is mechanical. Pulling a renewal date out of a transcript. Sorting an inbound into expansion or churn risk. Cleaning a title. Picking which branch of a play to run. Those go to a small, fast model. You reserve the premium reasoning model for the one call that earns it: given the worked-out state, what's the next best move on this account, and why?
Here's what that looks like on a real deal-risk workflow:
Risk scoring, the old job of a mid-tier LLM, now belongs to a fit model that runs on change and costs almost nothing per read. The LLM layer handles the two things models can't: reading prose and reasoning about the worked-out picture.
The confidence gate: when cheap becomes expensive
The tiers above are defaults, not rules. Every step returns a confidence score, and a step that comes back unsure escalates rather than committing:
- LLM layer: A renewal date Haiku extracts at < 0.85 confidence reruns on Sonnet instead of writing a guessed date to the CRM.
- Model layer: A risk score the model isn't sure about routes to the Opus synthesis step for a second look instead of landing green in the deal-health field.
You tune the threshold against your own eval set. Too low wastes savings, too high lets bad answers through.
Why this matters: the dangerous failure is the quiet one. A renewal note reads "happy overall, just reviewing options for next year." The risk model scores it green at 0.71. With the confidence gate off, that score writes straight to the deal-health field. No alert fires, no save play opens, nobody multi-threads, and the renewal slips a quarter. Every agent and forecast downstream inherits the wrong answer as fact.
The model saved a fraction of a cent on that score. The wrong value cost the renewal. A token, or a score, that writes a wrong value to the CRM is the most expensive one in the workflow.
What works and what's missing: a cost-reduction comparison
The first four are worth doing. They work above the waterline. The rework is below it.
Why this isn't just caching or retrieval
These three get conflated, but they save different things:
- Prompt caching reuses identical text repeated word for word. Helps for a fixed system prompt. Does almost nothing for deal context, because the data differs per account and changes between calls.
- Retrieval (RAG) picks which raw records to load. You still read them in and still make a model reason over them every call.
- Pre-materialized context reuses the result of thinking about inputs that change per account. You save the reasoning itself, not just the repeated text or the selected records.
In a revenue stack, the expensive repetition is the model working out the state of an account, not boilerplate. That's the layer to target.
Where the 30–70% savings actually comes from
When someone claims a range that wide, ask where each piece lives.
- Killing the rework (the bulk). If your agents rebuild the same account on most calls, storing that result removes the biggest line item: pure repetition. On a stack that scores the same book every night and answers questions about it all day, this is the cheapest cost reduction that exists, because it's spend you simply stop creating.
- Model routing (additive). Once the context is a small object, matching each step to the right model adds to the rework savings instead of overlapping them. The expensive model reads a brief, not a raw account, so even its calls shrink.
- Cutting runs that never needed to happen. A real chunk of agent spend produces nothing: runs on cold accounts, work another agent already did this morning, plays on deals that already closed. You can't store or route your way out of this. You have to see it first, at the level of cost per account and per outcome. The bottom of the range is architecture. The top means cutting the runs that never should have started.
You can build this yourself. The hard part is keeping it.
Everything above is buildable. If you have the engineering time, build it.
It's also a real system to own: a context store that versions and serves the worked-out state so it doesn't drift from the CRM. A router with evals so a cheap model never quietly ships a wrong answer into a field. And the attribution layer to tie every run to an account and an outcome, the piece that turns "we think we saved money" into a number.
How Loop does this for you
Loop is that layer, built so you reduce AI agent costs without standing up the plumbing yourself.
It “materializes” and serves the context.
Loop derives your revenue context once and routes the right slice to every agent and seller in a single MCP call. Pre-materialization as a product rather than a project. The agent stops rebuilding the account from a raw CRM dump because the worked-out state arrives ready. Work an agent does no longer evaporates when the session ends; it feeds back into the context the next call reads.
One early user, a RevOps leader, Quincy, landed on the same logic from the buyer's seat: the savings comes from pulling "these analytics upstream" so the platform serves a targeted answer instead of leaning on a giant context window, and burning hundreds of thousands of tokens to rebuild it every time.
- It attributes the spend. Loop ties every agent, every activity, and every token to the deal it touched and the outcome that followed. Cost per account. Cost per closed-won. Attributed revenue against the agents that earned it. The usage dashboard told you an agent ran. Loop tells you what the run was worth, which is the only way to find and cut the spend that produces nothing.
- It learns what works. A private model, scoped to your org and trained on your deal cycles, finds the predictors that move close rates and promotes them, then suggests the next play. That's the difference between agents that burn tokens on every account equally and agents pointed at the work that closes.
Before the next argument about the price of a token
Ask a different question: how many times did your stack process the same deal today, and how many of those runs did you actually need?
FAQ's on:
Context engineering / LLM cost optimization for RevOps
It means an agent re-runs thinking it already finished. The common case: a risk step reads the same records and reaches the same conclusion call after call, because the first result was never saved. Save the worked-out result once and reuse it, and the duplicate work disappears.
It matches each step to the smallest model that can do it right, and only escalates when the step is genuinely hard. Pulling a date from a transcript goes to a small model; an ambiguous strategic call goes to a stronger one. The choice rests on how hard the step actually is, often backed by a confidence check, not a fixed rule.
Not when the tiering matches how hard the step is and you check the output. Small models are reliable on bounded tasks like pulling a renewal date, tagging intent, or summarizing a known field. The risk is a quiet drop where a cheaper model degrades a score and nobody notices until it hits the CRM. The fix is to keep a trace of what each step produced so a drop stays visible.
Usage tells you how many tokens ran. Pipeline tells you whether the run mattered. Connecting them means joining what an agent did to the account it touched and the outcome that followed, so a run reads as useful or wasted instead of just counted. This is harder than logging usage, because the spend and the CRM usually live apart.
No. Prompt caching reuses identical text that repeats word for word, which helps for fixed boilerplate. Storing context reuses the result of thinking about inputs that change per account, so you save the reasoning itself, not just the repeated words. In a revenue stack, the expensive repetition is the model working out the state of an account, not boilerplate.
Why stop now?
You’re on a roll. Keep reading related write-up’s:

.png)

Draft with one click, go from DIY, to done-with-you AI
Get an executive-ready business case in seconds, built with your buyer's words and our AI.
Meet the sellers simplifying complex deals
Loved by top performers from 500+ companies with over $250M in closed-won revenue, across 19,900 deals managed with Fluint

Now getting more call transcripts into the tool so I can do more of that 1-click goodness.



The buying team literally skipped entire steps in the decision process after seeing our champion lay out the value for them.


Which is what Fluint lets me do: enable my champions, by making it easy for them to sell what matters to them and impacts their role.

