
What Is GTM Judgment? The Tacit Knowledge Layer That Compounds for RevOps

TL;DR
The RevOps job is shifting from configuring tools to engineering the context that revenue agents run on. Call it context engineering. The plumbing is the easy part. The hard part is judgment: which play to run, for which stakeholder, at which moment, based on what's actually closed before. Foundation models commoditized execution, so anyone can draft a business case now. They didn't commoditize judgment. It lives as tacit knowledge in your best operators, and almost nobody has built a system to capture it. GTM Judgment is that layer: it encodes the tacit knowledge, wraps it around every deal as ready-to-use context, and compounds it every cycle. Without it, AI in revenue is a faster engine pointed nowhere.
What is GTM Judgment?
Start with where the value went. In an AI revenue stack, the model is now the commodity. Everyone runs on the same general-purpose frontier models. Execution rides on top of them and is just as cheap. The scarce layer, the one that's hard to copy and gets more valuable the longer you run it, is context: knowing which play applies to this deal, right now, based on what's actually worked in comparable ones. Value migrates from the model, to the context, to the application. GTM Judgment is that context layer, and engineering it is the part of the RevOps job that can't be bought off the shelf
It's the layer that captures and applies tacit knowledge: the instincts, pattern recognition, and situational awareness that separate your top operators from everyone else. Any agent can follow a process. Judgment tells the system which process applies to this deal, right now, based on what's closed before.
Think GPS versus wayfinding. A GPS gives you turn-by-turn directions; that's the playbook. Wayfinding figures out a dozen routes that vary by terrain, weather, and conditions, and knows where the map is wrong. Execution is the GPS. Judgment is the wayfinding.
What's the difference between tacit and explicit knowledge in sales?
Explicit knowledge is everything you can hand someone on day one:
- Playbooks
- Battle cards
- Objection-handling scripts
- Email templates
- Onboarding docs
Searchable, shareable, ingestible by any AI tool. Fine. Also nearly identical across every team in your market.
Tacit knowledge is everything else: the instinct that says push for a next step here, let this one breathe. The pattern recognition that clocks a deal as quietly dying three weeks before it formally stalls. The call about which procurement stakeholder to engage before IT gets looped in, and why.
By definition it can't be documented. Most of your best operators couldn't explain it if you asked them to. It gets built across hundreds of closed cycles, absorbed through repetition, and shows up as judgment in the moment.
Explicit knowledge is the framework. Tacit knowledge is how you know when to break it.
The familiar shape of it: a small fraction of the team drives most of the revenue, even though the explicit toolkit is shared evenly. The gap isn't the decks or the scripts. It's almost entirely tacit.
Why can't standard AI tools capture tacit knowledge?
Most AI tools aimed at revenue are a frontier model pointed at explicit inputs: a call transcript, a CRM record, recent emails. They're good at that. What they can't do is read the trajectory of a deal over time. Tacit knowledge lives in the motion between the data points, and a single frame has none of it.
A model looks at a deal like a photo. It sees a single frame and generates something plausible about that moment.
Enterprise deals are videos. A champion going quiet for six days in week three of a 90-day cycle means something completely different from the same silence the week before a renewal. A 7:30pm Friday procurement email from an exec who can't wait to get moving is a different signal than the same email arriving Wednesday mid-morning. The meaning lives in the sequence, the spacing, and the velocity.
A prompt-based system only ever sees the current frame. It can't warn you a deal is dying three weeks out, because it has never watched the other deals die. The output reads fine and tells you nothing you didn't already know.
That's why these tools plateau: they're working from a photo when the story is in the film.
This is also why Fluint doesn't compete with Claude, ChatGPT, or Copilot. We plug into them and make them smarter on revenue work. The frontier model is the engine. We supply the context that tells it where to aim.
What is GTM Drift?
GTM Drift is what happens when tacit knowledge never gets captured and compounded: the org slowly drifts off the path to revenue and doesn't notice.
It runs at two levels:
- Org Drift. Company-wide. Messaging that used to land stops landing. New hires get trained on what used to work. Nobody notices until the number moves.
- Deal Drift. Individual. A deal that should close starts to wobble. The wrong stakeholder gets looped in. A signal gets missed. A champion goes quiet and nobody catches the pattern. The deal slides sideways, and nobody (rep, manager, dashboard) can say why until after the fact.
The only real defense is a system that continuously captures what's working, adapts as conditions change, and course-corrects in real time. Your sales process can't fix it. Neither can better prompting. It's a data-and-judgment problem.
How does GTM Judgment compound over time?
A static playbook and a one-off prompt both stop improving the moment you finish them. A judgment layer doesn't.
The reason most agent setups never improve is that the loop is open. An agent acts. A dashboard says "it ran." Then nothing, because agents don't carry a quota, so nobody measures them against revenue. No attribution, no feedback, no learning. The agent runs the same play next quarter whether it worked or not. That's GTM Drift with a machine driving.
A judgment layer closes the loop:
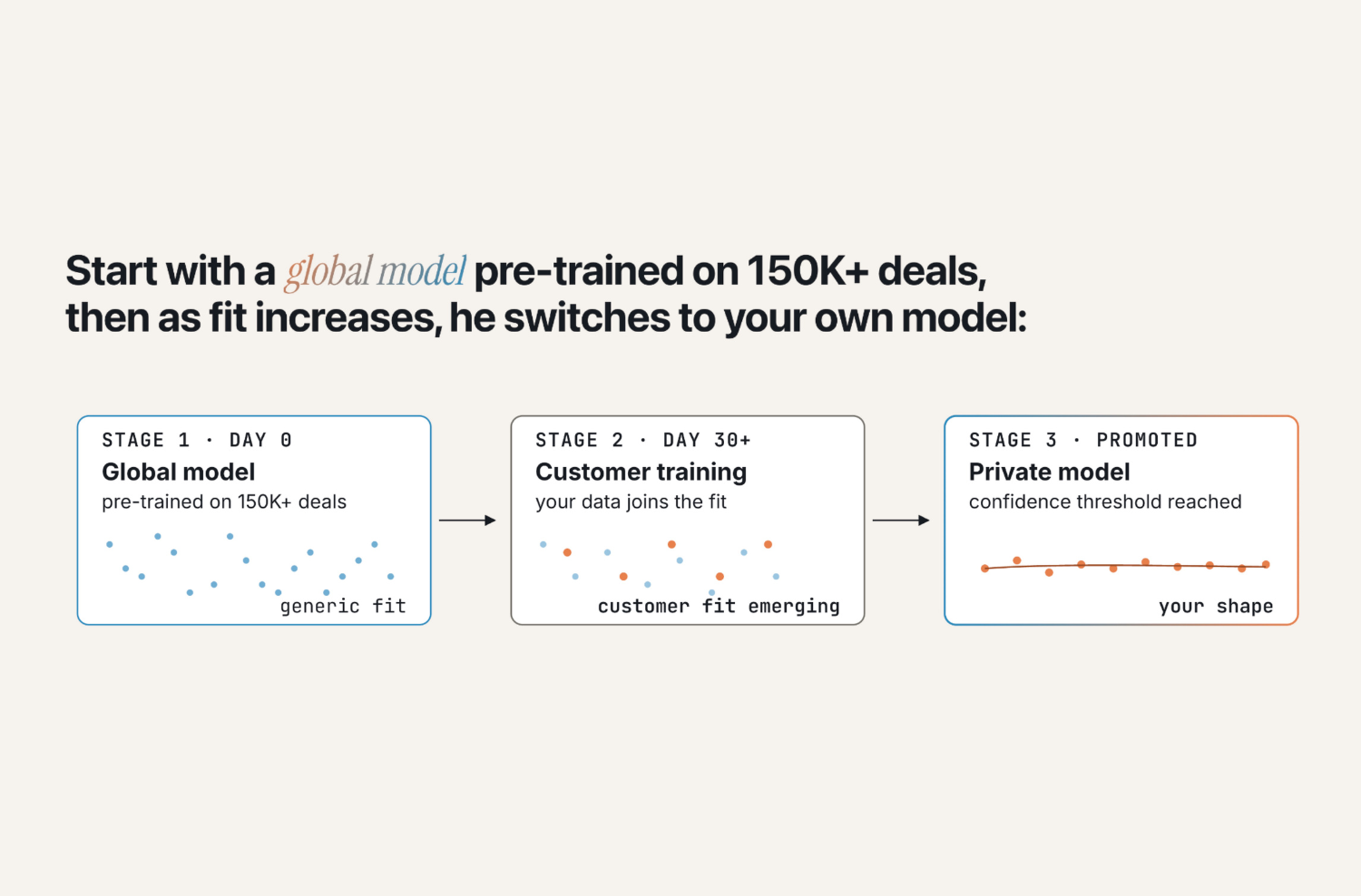
- The managed Agent runs a deal on Loop's pre-materialized context, drawing on patterns from 150,000+ outcome-linked cycles.
- The trace of what it did, plus the rep's adjustments and the deal's intent, get joined back to the CRM record.
- Your private ML labels the outcome: won, lost, stalled, and why.
- The next call to Loop carries that. The Agent gets sharper on your buyers, in your segment, against this profile, not on industry-wide averages.
A playbook captures explicit knowledge at a point in time. A living judgment layer keeps incorporating the tacit knowledge your team generates every cycle. It sharpens instead of drifting. And because every agent action is now tied to a deal outcome, you can answer the question RevOps actually gets asked: what did the agent make us, and how do we know?
What does GTM Judgment look like in practice?
Four layers make it work. Together they're Loop, the context platform every Fluint customer runs on. Loop is the nucleus: no other product works without it, and every customer has it. Loop is also the MCP. The protocol routes the request, Loop generates the context it serves.
Every cycle makes the next one sharper. That's the compounding mechanism, and it's why a snapshot can't catch up to it.
Why is GTM Judgment hard to build in-house?
Three reasons this is hard to copy, and gets harder the longer it runs.
- The data pipeline is brutally hard. Getting clean, normalized, time-series data out of a full GTM stack (Salesforce, HubSpot, Gong, Outreach, Gmail, Slack, document engagement) and structuring it so a model can learn from it is expensive, unglamorous work. We've been building this pipeline for years. A team standing up agents over a sprint isn't rebuilding it.
- The outcome labels are earned, not bought. The ground truth that makes a deal model useful is what actually happened to the deal, and why. You can't scrape that. You earn it by sitting inside real cycles, watching them resolve, and feeding outcomes back in: the closed loop, run thousands of times.
- Reproducibility ends at the data layer. A team with a frontier model and a good prompt can reproduce a snapshot. They can't reproduce a library of 150,000+ enterprise cycles with structured time-series signal and outcome labels across many orgs. That takes years of product, pipeline, and customer trust. It compounds in a way a prompt strategy never will.
This is the real decision in front of RevOps right now, and it isn't build vs. buy. It's build vs. start: start three years behind a system that compounds every cycle, or run on one that already does.
Why we built Loop around GTM Judgment
I've spent a lot of time inside enterprise GTM orgs. The same problem kept showing up regardless of company size, stack, or how sophisticated the team was.
The gap between top performers and everyone else wasn't the process. The people who'd been in the trenches long enough had built a kind of situational intelligence (about buyers, about deal trajectories, about when to push and when to back off) and it couldn't be transferred. It lived in them. When they left, it left too. Nobody had built a system to capture it.
Most of the AI we looked at was solving the execution problem: faster content, better templates, automated follow-up. Useful. But it made the engine faster without knowing where to point it. We kept watching teams with great tooling lose deals they should have won, because the judgment layer was missing. The layer that knows which play to run, for this deal, right now, based on what's worked before.
That's what Loop is built to do: encode the judgment of your best operators as context, wrap it around every deal in the pipeline, and compound it with every cycle that runs. RevOps is increasingly expected to engineer revenue outcomes, not just configure the SaaS tools underneath them. An engineering layer for revenue operations is what makes that possible: a system that captures what your strongest people know and gets sharper every quarter.
Go deeper
- Read the internal memo → The strategic brief we shared internally on GTM Judgment: where AI in enterprise revenue has missed, and what it needs to do instead. Worth ten minutes.
- The technical guide: build vs. start → The full breakdown of the five systems required to build a judgment layer in-house: time-series data architecture, tacit-knowledge capture, deal scoring, and the rest. Required reading if your RevOps or engineering team is evaluating this internally.
- See the judgment layer in a live pilot → If you want to see how Loop works inside a live enterprise revenue motion, we'll set up an integrated pilot.
FAQ's on:
A playbook captures explicit knowledge: documented processes and best practices at a point in time. GTM Judgment captures tacit knowledge: the instincts, pattern recognition, and situational awareness top operators develop over hundreds of cycles and can't articulate. A playbook tells you what to do. GTM Judgment tells you what to do in this situation, based on what's actually worked in comparable ones.
No. Frontier models operate on a single frame of context. They're stateless by design and can't model the trajectory of a deal over time. GTM Judgment requires ML trained on time-series outcome data: the sequence, velocity, and spacing of deal signals mapped against won and lost results. A model alone generates plausible outputs from a snapshot. It can't tell you a deal is dying three weeks before it dies.
Explicit knowledge is everything that can be documented: playbooks, scripts, battle cards, onboarding materials. Tacit knowledge is the judgment that can't be written down: the pattern recognition and situational instinct top operators build through experience. Explicit knowledge is teachable. Tacit knowledge has to be observed, modeled, and encoded at the behavioral level.
Tacit knowledge that never got captured, plus a feedback loop that stays open. The org slowly diverges from the patterns that actually drive revenue. Org Drift is the company-wide version: messaging that used to work stops working, new hires get trained on outdated patterns, nobody notices until revenue drops. Deal Drift is the individual version: a deal wobbles because a signal got missed or the wrong stakeholder got engaged, and nobody catches the pattern in time.
Most tools operate on explicit inputs (transcripts, CRM records, emails) and generate outputs from that snapshot. Loop models the trajectory of a deal over time using ML trained on 150,000+ comparable cycles plus each customer's own won/loss data, then serves that as pre-materialized context to whatever agent is doing the work. The difference is between an AI that reads what's happening now and one that knows what this deal trajectory has historically led to, and closes the loop so it keeps learning.
Why stop now?
You’re on a roll. Keep reading related write-up’s:

.png)


Draft with one click, go from DIY, to done-with-you AI
Get an executive-ready business case in seconds, built with your buyer's words and our AI.
Meet the sellers simplifying complex deals
Loved by top performers from 500+ companies with over $250M in closed-won revenue, across 19,900 deals managed with Fluint

Now getting more call transcripts into the tool so I can do more of that 1-click goodness.



The buying team literally skipped entire steps in the decision process after seeing our champion lay out the value for them.


Which is what Fluint lets me do: enable my champions, by making it easy for them to sell what matters to them and impacts their role.

