The Complete Guide to Building an AI Agent for Enterprise Sales: The 5 Compounding Systems

Context
Most AI sales tools are chatbots with a CRM integration bolted on. That's not a judgement; it's just a description of what you get when you wrap an LLM in a UI and point it at your pipeline data. You get a tool that answers questions when you ask them, forgets everything when you close the tab, and calls it "AI-powered."
This is your guide on how to not build that.
It’s a walkthrough of what we actually built inside Fluint, to make Olli, our AI agent, work the way we think an AI agent specifically designed for complex, strategic sales work should work:
Retaining context over time, scoring deals with statistical rigor, encoding the “gut feel” and intuition behind what your best reps know and do, while surfacing the right information—before you have to ask for it.
Which I'm about to walk you through in a pretty open, transparent way. Because if you're a RevOps leader or an engineering manager trying to decide whether to build something like this in-house, we want to set you up for the best shot internally. For some of you, you can get “far enough,” without needing to hire Olli. This is your guide. And for too many more, we’ve watched too many teams fall into the gap between, "We have access to all the major LLM’s too," and, "We have a system that actually learns and compounds." It’s wider than it looks. So, here’s your bridge.
What you need to know, and how to build, system by system.
The Stateless Problem: Why Most AI Doesn't Actually Learn
Let's start with what LLMs actually are, technically, because a lot of the confusion in the market starts here.
1. An LLM is stateless by design.
Every API call starts from zero. There is no persistent state between calls, no internal memory of the last conversation, no awareness of what happened yesterday. The model receives a prompt, generates a response, and that's it.
The next call has no inherent knowledge of the previous one. This is a deliberate architectural choice, one that makes LLMs scalable, but it has a direct consequence for anyone trying to build something on top of them.
2. Most AI products built on LLMs inherit this limitation.
They don't solve it. What they do instead is re-fetch context at the start of each call: pull the conversation history, inject it into the prompt, and let the LLM respond as if it has memory.
This works fine for a chatbot where the conversation is short and context is self-contained. It breaks down when you're trying to build something that genuinely learns over time.
Most AI products call what they ship "memory."
The problem isn't the word — it's that what they're actually shipping is history. There's a real difference between the two.
History is a transcript. It's a written record of what was said. Memory is something richer: context, trajectory, the external factors that were present in a given moment. Think about a childhood memory. You're not just recalling a sequence of words from a conversation. You're remembering what was happening on the playground, what the weather felt like, the emotional texture of that moment. Multiple data points come together to make it a memory rather than a record.
So what most AI products are doing is giving you a very sophisticated transcript. They're storing what you said and feeding it back. That's history. Memory requires understanding the context — the variables surrounding a situation, not just the words exchanged in it.
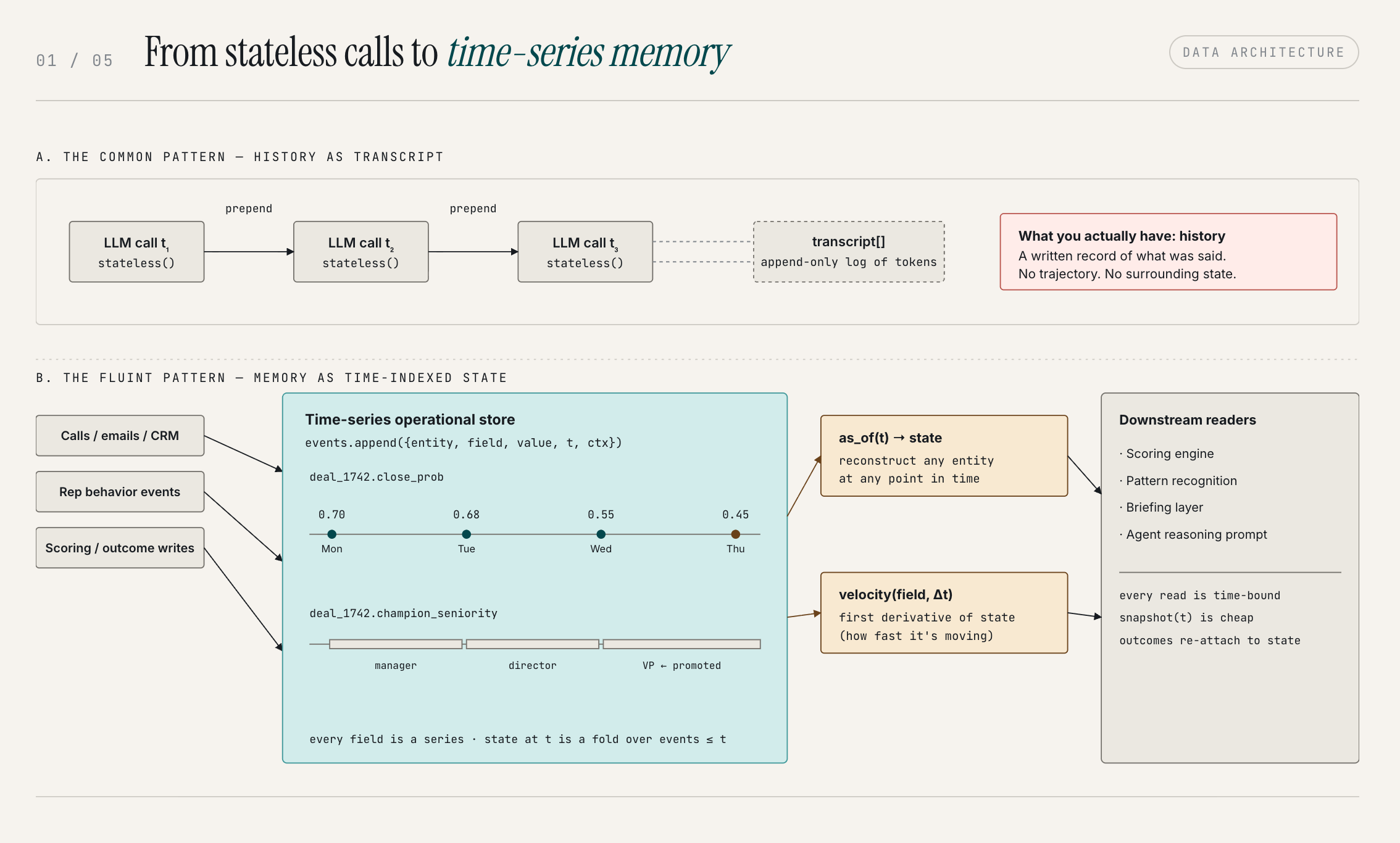
To build something that actually learns, something that can trace the reasoning about the trajectory of a deal over time, notice the behavioral shifts in how reps interact with the system, and connect a pattern you see in Q3 to something that happened in Q1, you need a fundamentally different data architecture.
To do this, we centralized all our operational data and built a separate data layer that specializes in time-series processing. The key design decision here: your operational data isn't static. It's always changing. A deal that was at 70% close probability on Monday, might be at 45% by Thursday. If you're training on or reasoning with that data, you need to be able to reconstruct what it looked like at any given point in time. You need to be able to rewind.
That time-series foundation is what makes it possible to analyze the actual velocity and trajectory of what's happening: not just the current state, but where things were, how fast they moved, and what was happening in the surrounding context when they did. That's the difference between a lookup and a memory.
If you want to build a system that genuinely learns from your sales data, this is the first major engineering problem you have to solve. Everything else depends on it.
Tacit Knowledge: The Things Your Best Reps Know, But Can't Explain
Every sales org has two categories of knowledge:
1. Explicit knowledge
the playbooks, the battle cards, the objection-handling scripts, the onboarding training. It's everything you hand a new AE on day one and say, "this is how we run deals here." Explicit knowledge can be documented. It can be searched. Any AI tool can ingest it.
2. Tacit knowledge
It's the thing your top performers have that you can't put in a training doc. It's the instinct that tells an experienced rep exactly when to push for a next step and when to let a deal breathe. It's the pattern recognition that says this deal feels different from that one, even when the CRM data looks similar. It's the gut feeling that comes from three hundred closed deals and a couple hundred losses.
Explicit knowledge tells you the framework. Tacit knowledge is the judgement that knows when to break it. So tacit knowledge is what actually gets deals done. But the challenge is that tacit knowledge, by definition, isn't documented.
You can't capture it by asking your reps to write it down. They can't explain it, which is the whole point. And you can't capture it by analyzing what people say in conversations alone. You have to observe what people actually do.
Here's how this flows through Olli:
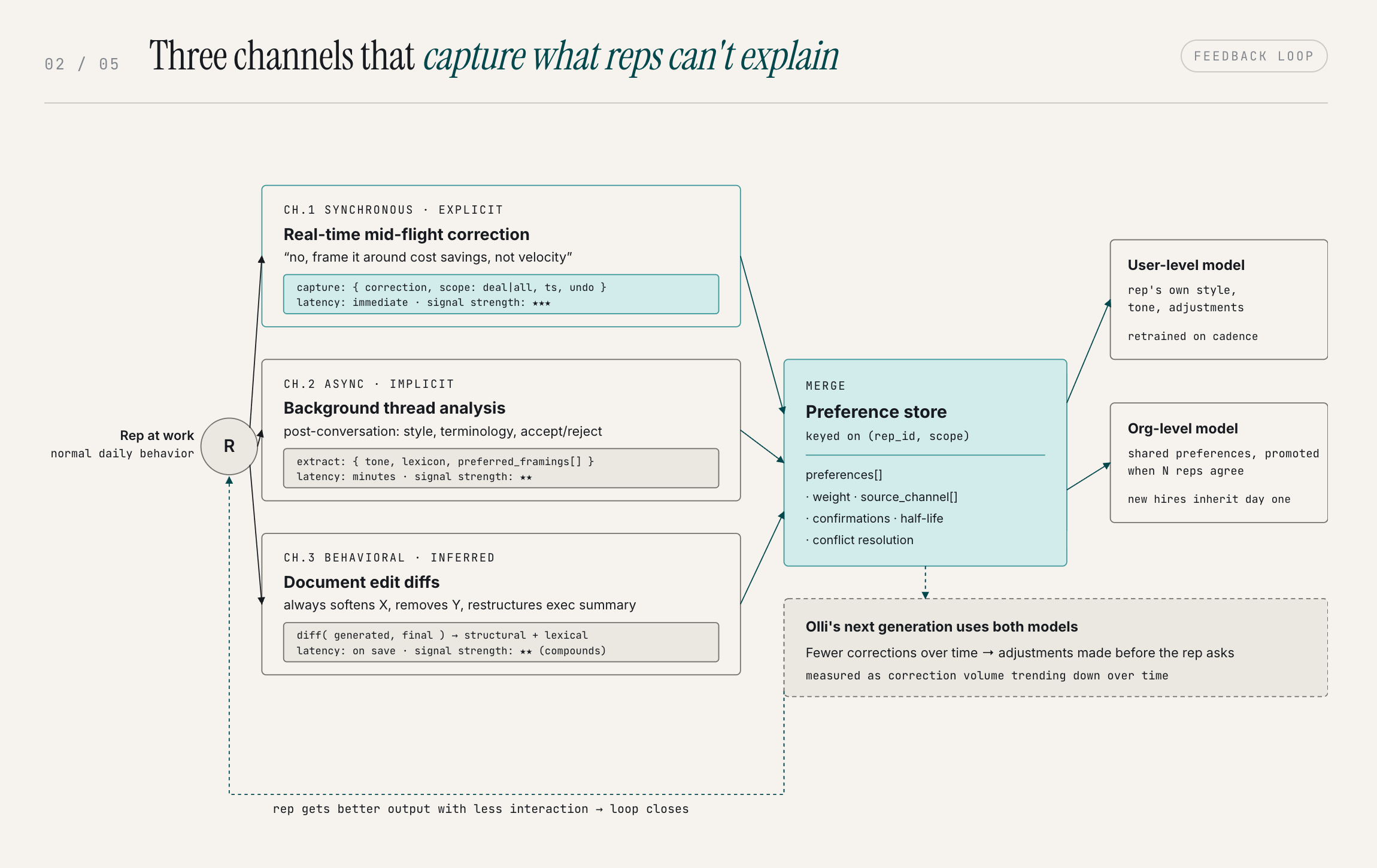
Behavioral signals come in through three channels, each catching things the others miss.
- Human in-the-loop corrections: When a rep redirects Olli mid-conversation ("no, frame it around cost savings, not velocity"), that correction is captured immediately.
- Background threads: After a conversation completes, Olli analyzes the full thread for implicit signals the real-time capture missed. The subtle stuff that never gets said out loud.
- Edit tracking: When a rep edits Olli-generated content, the diff reveals preferences they never explicitly stated. Over multiple documents, content-level patterns emerge that no single edit would surface.
All three channels feed the same preference store. Over time, Olli stops needing to be corrected on the same things. It learns the rep's style, their patterns, the specific adjustments they consistently make, and it starts making those adjustments on its own.
The rep gets more value with less interaction, which is what actual automation is supposed to do.
At the organizational level, this compounds further. When multiple reps share the same preference, it becomes org-level knowledge. A new rep benefits from that institutional intelligence on day one — without a ride-along, without a training doc.
That's tacit knowledge, captured at scale and made visible. You can't get there by ingesting documents or uploads. You get there by watching what people actually do and building a system that can learn from it.
This is the second major system: a feedback loop that captures behavioral corrections across three channels and trains them back into the model continuously.
Why LLMs Can't Score Deals: The ML Layer

Here's a question worth sitting with: if you asked GPT-5 to rate your current pipeline on a scale of 0 to 100, what would you actually be getting?
You'd be getting an opinion.
A well-articulated, plausible opinion, but an opinion. LLMs are optimized to interact with humans in a human-like way. That means they're opinionated by design. They reason the way a person reasons: through language, through analogy, through patterns learned from human-generated text. That's a feature when you need communication. It's a serious problem when you need math.
But scoring is a math problem.
You're trying to quantify probability based on a set of observable signals: deal velocity, engagement patterns, stakeholder involvement, competitive presence, historical comparables. You need statistical rigor, not prose reasoning.
The right tool for that is a dedicated ML model, not an LLM.
Think about it this way: I want the person managing my company's finances to be laser-focused on numbers. I want the person handling communications and PR to be exceptional at language. Picking the right tool for the right job isn't a compromise; it's the whole point.
The architecture we built separates these functions deliberately.
- The LLM handles signal extraction from unstructured sources: call transcripts, emails, Slack conversations, meeting notes. It's good at that: understanding the behavioral content of a conversation, identifying what's significant, summarizing and aggregating qualitative data into a form that can be analyzed. That's a language problem, and LLMs are the right tool.
- Once the signals are extracted and structured, the ML model takes over for scoring. It evaluates deals across several dimensions. Two key dimensions are whether a champion has been identified and how senior and engaged they are, and whether the economic buyer has been directly engaged. Pure math. No opinions.
Each dimension returns a score, an LLM-generated plain-language explanation of the reasoning, and a confidence level based on data completeness. Those dimension scores roll up into a composite deal health score through a weighted model — not a simple average.
One specific thing we surface alongside scores is a confidence level, and this distinction matters more than people initially realize.
- A score of 85 with high confidence is a fundamentally different thing from a score of 85 with low confidence. The score tells you where a deal stands. The confidence level tells you how much data we have to back that assessment. A high-probability score with low confidence means the deal looks good, but we don't have enough signals to be certain. A slightly lower score with high confidence is a safer bet. You know what you're working with.
- The ML model retrains on closed-won and closed-lost outcomes, and it builds from there. Historical data gives us a starting point, but the model gets substantially sharper after processing your org's actual pipeline, established with a custom threshold of number of deals required to become statistically significant. The reason for that threshold is statistical: the more data points you have, the less any single anomaly skews the mean. One bizarre outlier deal can throw off a small sample.
That said, value doesn't wait until deal 1,000. You'll see Olli tuning its output and improving its recommendations on outbound messaging and judgement calls from the start of the process. The flywheel builds over time — it doesn't flip on at a threshold.
This is the third major system: a dual-layer architecture where the LLM handles extraction from unstructured data and the ML model handles scoring, with confidence levels surfaced alongside scores and the model retraining continuously on closed outcomes.
Briefings, Not Interrogations: The Proactive Layer
Think about what a dashboard actually is. You go to it. You pick the filters. You decide what to look at. You ask it questions, it shows you answers, and then you interpret what that means.
Dashboards are interrogation tools. And they have a fundamental flaw: they assume you already know what you need to see. They surface what you ask for. What they don't surface is what you haven't thought to look for. In my experience, that's exactly where deals die.
The things that kill pipeline aren't usually the things you're tracking. They're the things you don't see coming.
We built Olli to be a coworker, not a search engine.
The difference is simple: a good coworker doesn't wait to be interrogated on the status of a project. They show up with a brief. They tell you what's changed, what matters, what needs your attention, without you having to pull it out of them. That's a fundamentally better experience, and it's the experience we're working toward.
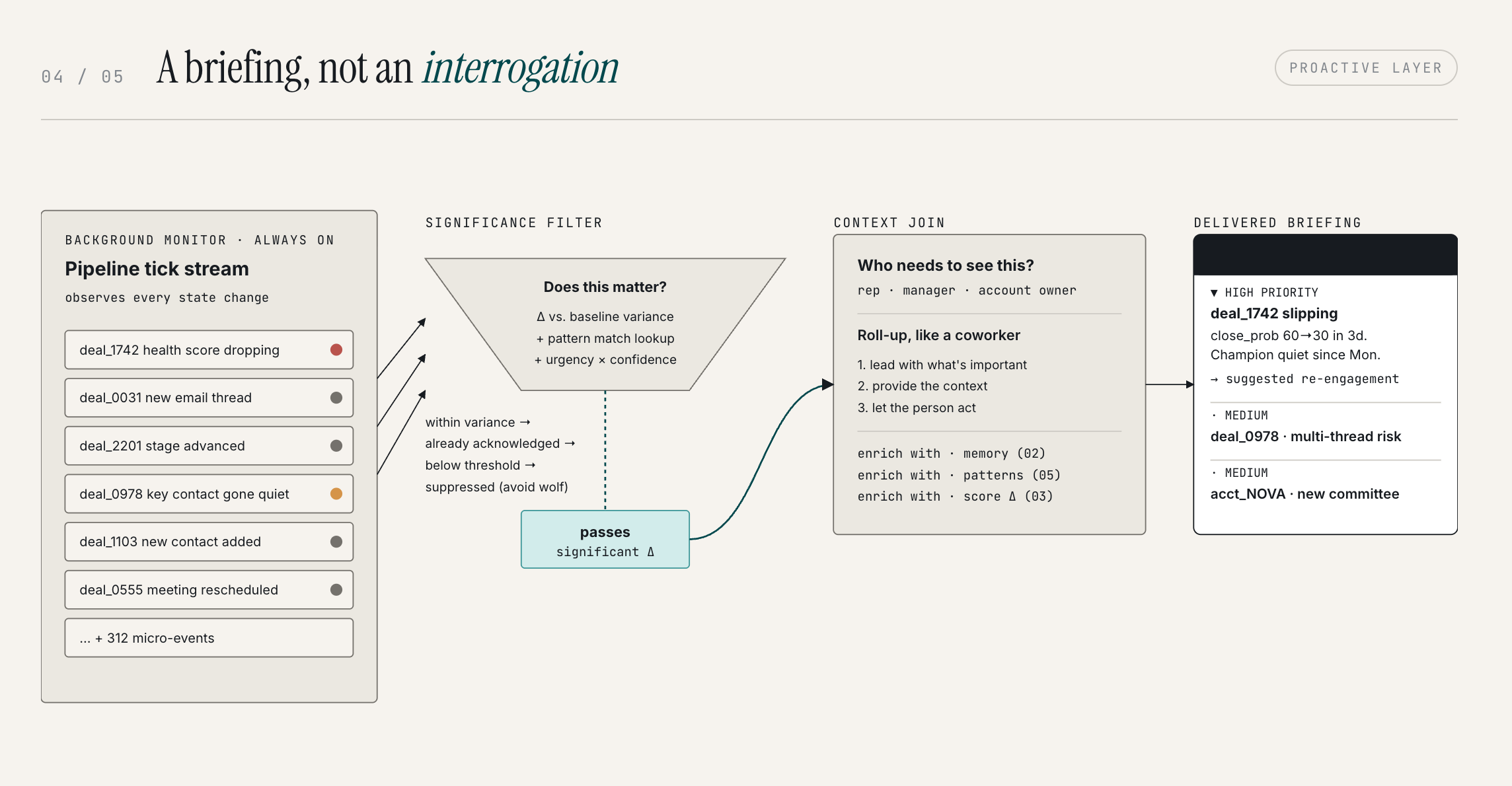
The proactive layer is what makes this possible.
It's constantly running in the background, monitoring signals across your pipeline, and evaluating what's worth surfacing. The threshold isn't "something changed." It's "something changed that matters." If a deal's close probability drops from 60% to 30% in a short window, that's a signal that deserves your attention now. If the drop is gradual and within normal variance, it doesn't need to interrupt you.
There's a credibility problem with proactive AI that's worth addressing directly. Everyone has been burned by alert systems that cry wolf: the Slack channel that flags everything, the forecast tool that's confidently wrong, the notification that fires so often you stop reading it. The desensitization effect is real. Once you learn to tune out a source of information, it's almost impossible to earn that attention back.
The way you solve this isn't by adding a settings panel where users can configure their own noise levels. It's by being right, being relevant, and not pinging people constantly. We roll up communications the same way a competent person would: lead with what's important, provide the context, let the person act. The prioritization is driven by actual analytics, real changes in real deal data, not activity triggers or arbitrary rules.
The briefing layer is the fourth major system. It's what transforms an analysis engine into something that actually shows up for your team.
Pattern Recognition: The Intelligence No Individual Could See
Memory makes Olli better at working with you. Scoring evaluates the health of individual deals.
Pattern Recognition does something different: it operates across your entire book of business to surface the insights no individual rep or manager would catch on their own, because they don't have visibility into their entire GTM dataset.
This is cross-deal, cross-rep intelligence that changes how a team sells. What deal profiles close at the highest rates? What combination of signals historically precedes a stall? What do your top performers do in the first two weeks that average reps don't? When a specific competitor shows up in discovery, which framing wins?
None of that is visible from inside a single deal. It only becomes visible when you can analyze across hundreds of them.
The specific patterns that emerge tend to fall into a few categories:
- Win/loss signals: deals with executive champions close at multiples of those with manager-level champions; deals where a business case was shared before the third meeting have materially higher win rates.
- Stall predictors: single-threaded deals with no next meeting scheduled and a champion who missed the last call follow a recognizable pattern before going dark.
- Competitive dynamics: when a specific competitor enters a deal, the framing that wins differs significantly from the default.
- Rep effectiveness: the behaviors that separate top performers from average ones aren't always obvious until you look across the data.
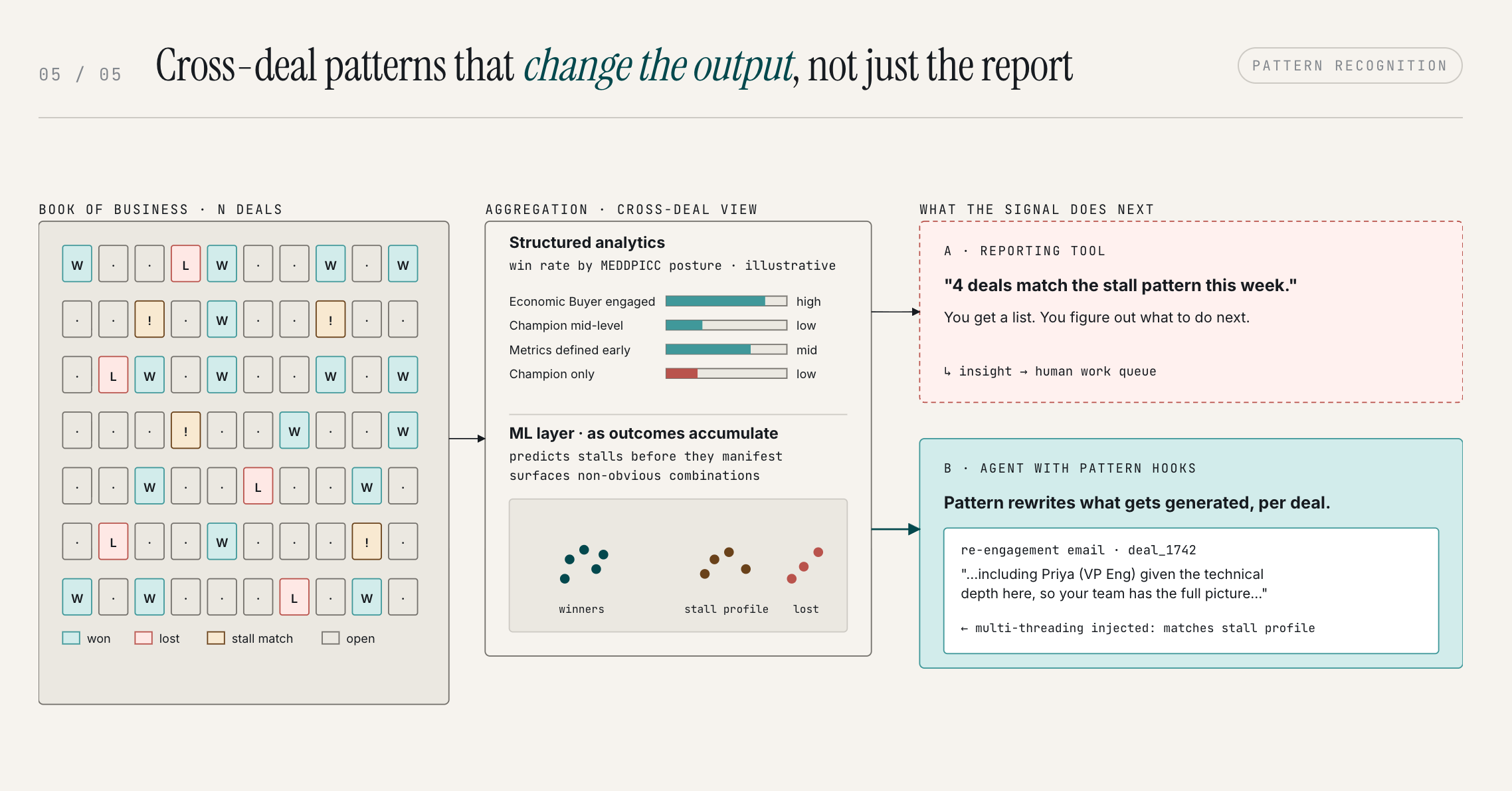
Here’s where Olli parts ways with every reporting tool you’ve used. A BI dashboard or pipeline report can show you these patterns. It can surface a stall risk, flag a competitive threat, tell you that single-threaded deals close at half the rate. That’s useful. But it still hands the problem back to you.
Olli doesn’t just report the pattern. It acts on it. The insight changes what Olli produces, in real time, before you have to make a decision.
The difference in practice:
- Reporting tool: “4 deals match the stall pattern this week.” You now have a list. You figure out what to do.
- Olli: “4 deals match the stall pattern this week.” And when you open any one of them and ask for a re-engagement email, the email is already written with multi-threading language baked in—because Olli knows this deal is single-threaded and that’s the pattern that precedes a stall.
The pattern doesn’t just surface—it changes the output. It changes what Olli generates for that deal, what it flags in a briefing, what it recommends in a pipeline review. A few specific examples of how this shows up:
- During mid-funnel work: "This deal matches the profile of six deals that stalled last quarter — the common factor was losing champion access after pricing. Consider re-engaging your champion before sending the proposal."
- During a pipeline review: "Four deals match the stall pattern this week."
- During content generation, Pattern Recognition doesn't just warn you, it changes what Olli produces. "Since this deal is single-threaded, I've included multi-threading language in the email."
Pattern Recognition starts with analysis on structured deal data — win/loss correlations, stall detection, competitive dynamics. As outcome data accumulates, ML models layer on top to predict stalls before they fully manifest and surface non-obvious signal combinations that aggregation alone wouldn't catch.
This is the fifth major system: cross-deal intelligence that connects the dots no individual could see and delivers them at the moment they're actionable.
The Full Build: What You’ll Have to Bring Together
Let's put the full picture together. We've covered five systems so far:
- Time-series data architecture that makes it possible to reason about the trajectory of your pipeline over time
- A three-channel feedback loop that captures tacit knowledge, and trains it back into user and org-level models
- A dual LLM-plus-ML scoring engine across eight deal dimensions
- A proactive briefing layer that surfaces what matters without being asked
- A pattern recognition layer that connects the dots across your entire book of business
Those five systems are necessary but not sufficient. Below them is an infrastructure layer that most teams who start this project don't anticipate until they're in it:
1. The async pipeline
Every piece of data that flows through Olli (call transcripts, emails, meeting notes, CRM updates) goes through an asynchronous processing pipeline. A transcript comes in, gets processed into insights, those insights roll up to deal level, the deal level rolls up to an account level, an account level rolls up to pipeline level. That's a cascade. And the cascade runs every time something changes.
The data hierarchy is like a reverse pyramid: the pipeline sits at the foundation, everything else stacks on top of it. When a single deal changes (one new call, one updated field, one rep correction), that change propagates up through every layer above it. Each object in the hierarchy gets its state invalidated and recomputed.
At scale, a small change in your operational data can trigger hundreds of thousands of operations. Your queuing infrastructure has to handle that without backing up or dropping state.
2. The ML training pipeline
Every time a deal reaches a terminal state (closed won, closed lost), we take a snapshot of everything: the signals that were present throughout the deal's lifecycle, the recommendations Olli made, which ones were acted on and which weren't, the final outcome. All of that feeds back into the model. We evaluate our own recommendations against results, and the model self-corrects accordingly.
This is a flywheel, and it's important to understand that all three intelligence layers feed each other — not just the scoring model. A deal's score starts trending down. Pattern Recognition identifies it matches a known stall profile. Olli generates a re-engagement plan, informed by Memory about what's worked for this rep and this deal type, and shaped by the competitive framing Pattern Recognition knows wins in this segment. The rep adjusts the plan — that correction feeds back into Memory. The deal advances or stalls, and that outcome feeds back into Scoring and Pattern Recognition.
Every interaction makes every layer smarter. That's the compounding effect, and it's the whole story.
3. The user interface for judgement
This is the piece most teams skip, and skipping it is a mistake.
There's no point in building a reasoning layer if users can't see the reasoning. If Olli makes a recommendation, the rep needs to understand why, not just accept a number. This is how trust gets built.
I use a parenthood analogy that I think captures it well: I don't trust someone with my children unless I've seen how they parent. You don't build that trust by being told the person is trustworthy. You build it by observing their decisions over time and developing confidence in their judgement. The same dynamic applies to AI. If a rep can see that a score of 72 is driven by a manager-level champion with no economic buyer access and a vague timeline, they can evaluate that reasoning. They can correct it if something's wrong. And over time, if the reasoning is consistently right, they trust it.
We think of this with an iceberg metaphor. Most AI products show you just the tip. The system is doing enormous work below the surface, but none of it is visible. What we want to build is a ship where you can see most of it, where the reasoning is exposed, accessible, and correctable, with just a small piece below the waterline that's necessarily obscure.
4. Security and infrastructure
We run self-hosted inference. That means we control our own data, we control the quality of our output, and we don't make tradeoffs on quality because of token cost constraints. When you're relying on an external API for inference, you're also relying on that API's reliability, its pricing model, and its data handling practices. Putting everything in-house removes those variables.
So, all together, here's the full inventory of what you'll need to stand up:
- A centralized data ingestion layer that pulls from all your operational sources and treats training data with the same security rigor as production data
- A time-series data store purpose-built for rewinding and analyzing the trajectory of your pipeline over time
- A tacit knowledge feedback loop that watches behavioral signals, identifies patterns, and retrains user-level and org-level models continuously
- A dual-layer scoring engine: LLM for signal extraction, ML for statistical scoring, with confidence levels surfaced alongside scores
- An async pipeline with a queuing system that handles cascading invalidation across a deal-account-pipeline data hierarchy at scale
- A closed-deal-to-model-retrain pipeline that snapshots state at terminal events and feeds outcomes back into the scoring model
- A proactive briefing layer that monitors your pipeline, prioritizes by real risk signals, and delivers communications that earn trust by being right
- A user interface that exposes Olli's reasoning so reps can see why a recommendation was made, correct it when it's wrong, and build genuine confidence in the system over time
That's the iceberg. The chatbot at the top is maybe 10% of it.
The Tradeoff
Building this in-house is possible. None of it is beyond what a capable engineering team can do. It's not magic. It's just a set of hard engineering problems.
The real question is whether this is where your engineering team should be spending its time.
Each of these systems requires ongoing maintenance, iteration, and improvement. The model doesn't stay sharp on its own. It needs to be evaluated against outcomes, retrained, adjusted when the business changes. The infrastructure needs to scale as your pipeline grows. The feedback loops need to be monitored for drift.
This isn't a project you finish. It's a system you operate.
There's also a compounding cost to waiting. A system like this gets smarter the longer it runs.
Every deal it processes, every correction it receives, every outcome it evaluates makes the next prediction sharper. An org that starts this process today will have a substantially more accurate system in twelve months than one that starts in twelve months. Every month you spend building is a month the system isn't learning your patterns.
That's the tradeoff. It's not build vs. buy. It's build vs. start. And if the answer is to start, the question is where to start from.
This is what we built Olli to do. If you've read this far and you're still thinking about building it yourself, that's a reasonable call. If you're not, you know where to find us.

Oh hey! If you made it this far... you might want to test drive Fluint
Fluint lets you apply everything in this playbook to the deals you’re working on, right now. Get an executive-ready content in seconds, built with your buyers words and our AI.