
AI Models for Revenue Teams: The Crash Course Nobody Gave You

TL;DR
- AI and LLM’s are not synonyms. LLMs are one specific tool inside a much larger AI toolkit. Most sales AI vendors only use LLMs and call it "AI."
- LLMs produce opinions. ML models produce facts. Discriminant ML models (like XGBoost and regression) give you deterministic, repeatable math. LLMs give you probabilistic guesses that change every time you ask.
- A predictor is not a tracker. Trackers look at signal frequency (correlation). Loop's predictors calculate explanatory weight against revenue outcomes (math). Same data, fundamentally different question.
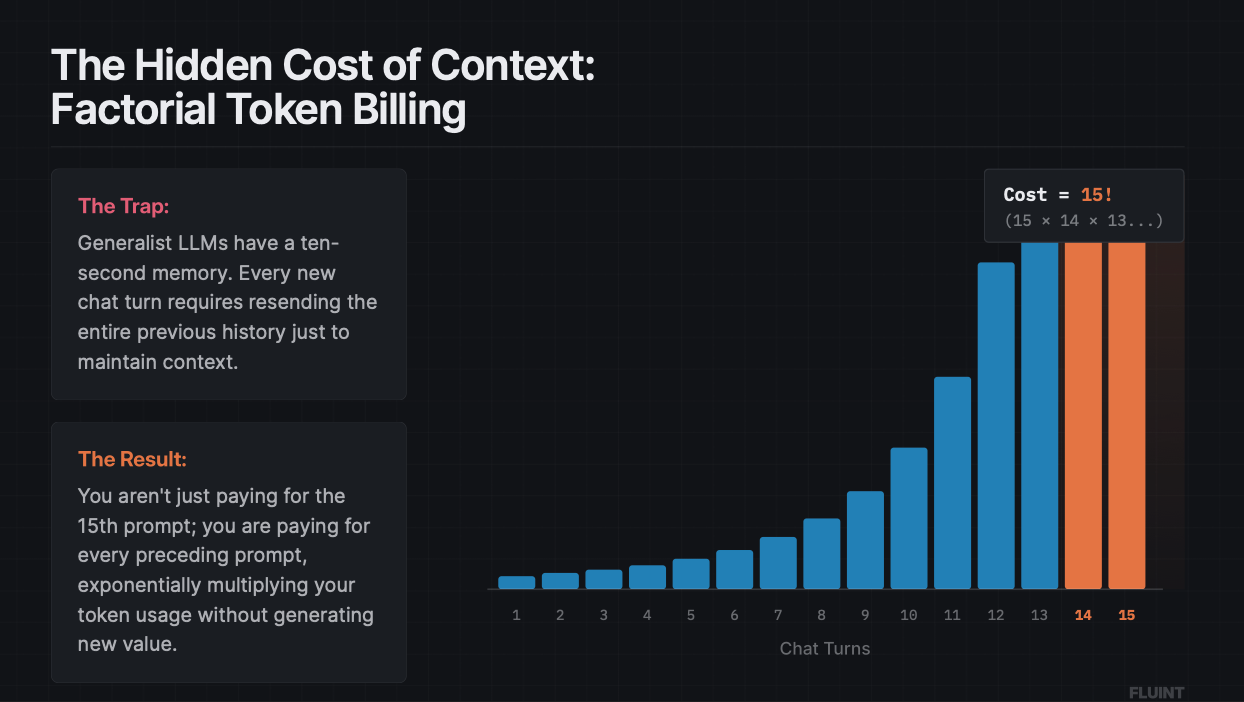
- Token billing is factorial, not linear. Your 15th chat turn doesn't cost 15 units — it costs the sum of all previous turns re-sent. Most teams have never calculated their real per-query cost.
- Bigger models aren't better models for sales. A trillion-parameter generalist dilutes your revenue data. A 35-billion-parameter model trained on sales cycles makes every fine-tuning adjustment count.
- Context engineering starts with math, not text. The right architecture scores variables with discriminant ML first and only hands the LLM pre-processed instructions to execute.
1. What’s the Difference Between AI, Machine Learning, and LLMs?
The market uses "AI" and "LLM" like they're the same word. They're not, they're not even close. It's like calling every animal a “cat.”
Think of it like Russian nesting dolls, where each one sits inside the one above it:
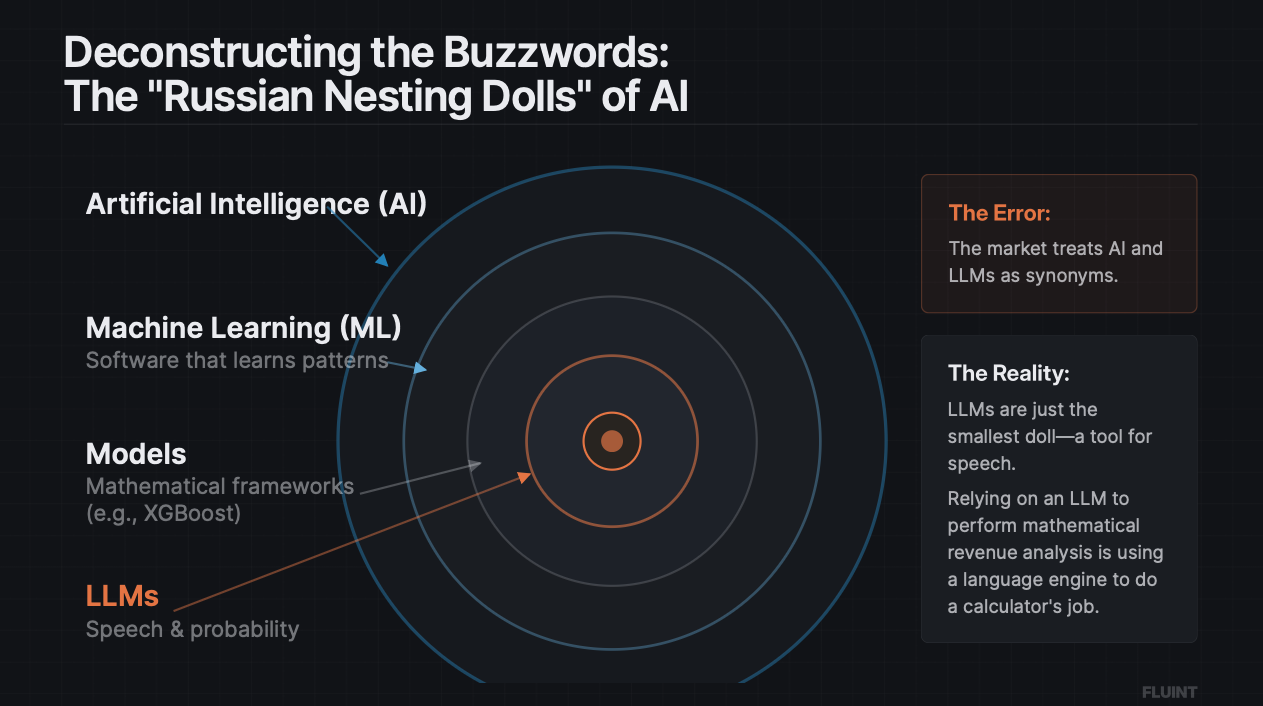
LLMs are the smallest doll. The innermost one. They're a single specialized tool inside a much bigger toolkit. When a vendor says they've "built AI for revenue teams" and all they did was wrap an LLM around your CRM data.
2. How Do LLMs Actually Work? (The Ten-Second Tom Problem)
If you've seen 50 First Dates, you know Ten-Second Tom. He meets you, has a conversation, and ten seconds later, he’s completely forgotten you exist.
That's an LLM.
Every single time you interact with one, it starts fresh with zero memory. You give it a prompt and some context, it does the math, it gives you a response, and then it's gone. The next time you send a message in the same chat, the system has to re-send the entire previous conversation just so the model knows what you were even talking about.
Which creates the feeling of memory (including the LLM running back through a day or weeks’ worth of conversations, then creating a file of notes to remind itself).
Because at the mechanical level, an LLM is a massive list of words, a massive list of probabilities for which word comes next, arranged in three-dimensional matrices, trained across billions of parameters. So, it's not “reasoning” in a traditional sense. It's calculating the most probable next word based on everything it was trained on.
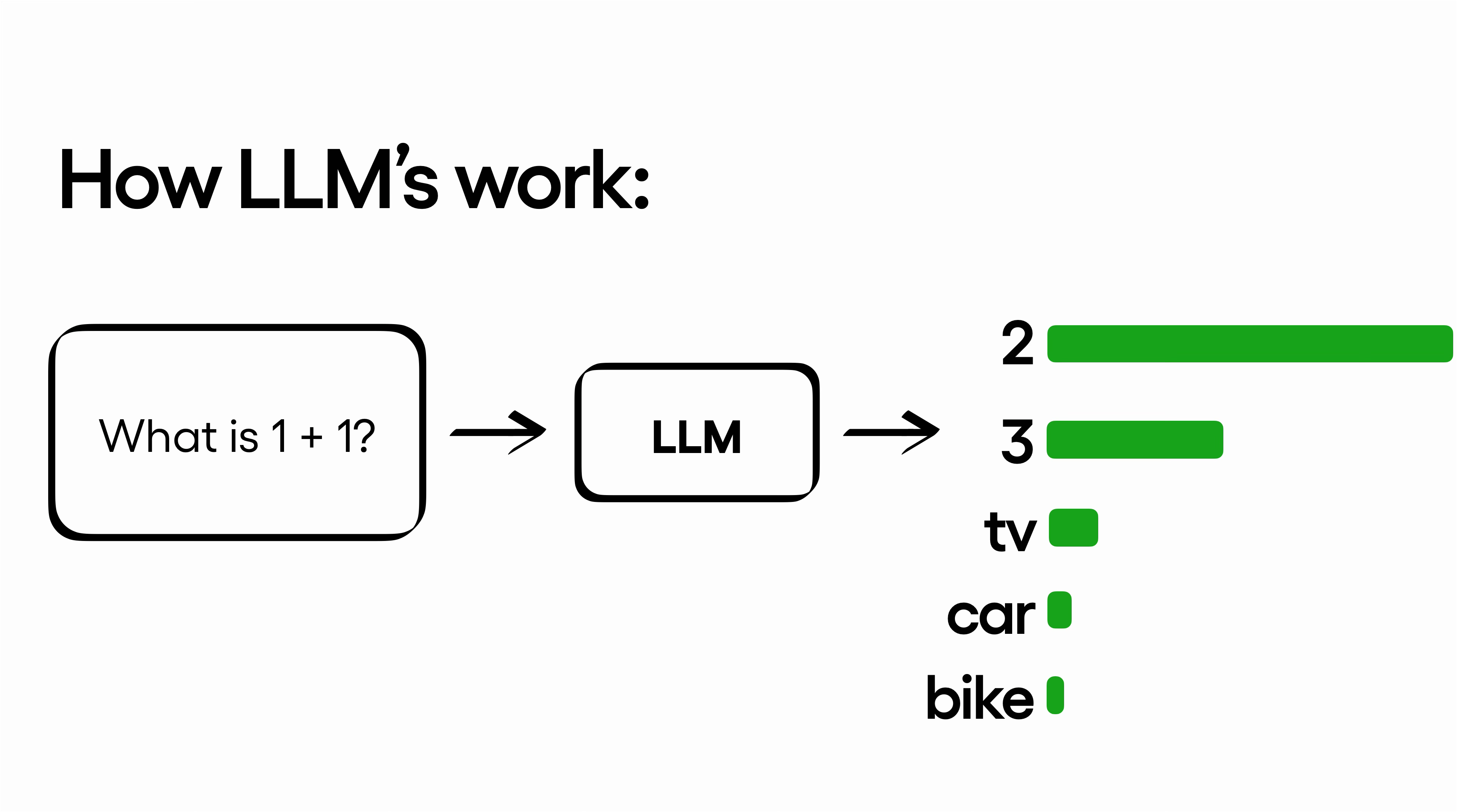
Three problems this creates for revenue teams
- Your context gets quietly thrown away. When a chat gets long, providers run a background summarization pass to compress the history. That summarization is lossy — the model makes calls about what to keep and what to toss. If it tosses something important about your deal, it doesn't know what it lost. It will answer you confidently based on incomplete data. And you'll have no idea.
- The model can't say "I don't know" without breaking. The fundamental math was designed to always produce an output. Always. Training it to say "I don't know" is like training a neural pathway in your brain — the more you reinforce it, the less resistance it has. Over-train it and the model just starts defaulting to uncertainty even when it has the answer. This is why hallucinations aren't bugs. The math is working exactly as designed. It's just that "always give an answer" and "always give a correct answer" are two different things.
- There are two different failure modes that everyone lumps together. The whole world calls everything a "hallucination" but there are actually two completely different problems:
They look the same to the end user.
The output is wrong either way. But the fix is completely different depending on which one you're dealing with. If your vendor can't tell you which failure mode caused a bad output, they don't understand their own system well enough to fix it.
What this looks like in practice:
Your reps get AI-generated deal summaries before calls. Some of the information is wrong. They don't know which parts. So they either trust all of it and walk into a meeting with bad intel, or they trust none of it and your AI investment is dead on arrival.
3. What’s the Difference Between Deterministic and Probabilistic AI Models?
It’s the part that separates people who understand AI from people who just use it.
In machine learning, there are two fundamental types of models. The sales AI market almost never distinguishes between them, which is kind of wild because the difference is everything:

Why aren't knowledge graphs and context layers enough for revenue AI?
Notion and Glean built really good knowledge retrieval systems. They find the right documents, map relationships between people and content, build context graphs that show who talks to whom about what. Sibyl does the same thing for sales specifically — org charts, influence patterns, buyer relationships.
But none of them score those relationships against a revenue outcome.
A context graph tells you that your champion talked to the CFO three times last month. That's a fact about a relationship. A discriminant model tells you that CFO engagement has a 0.92 explanatory weight on closed-won deals in your specific org — and that champion-to-CFO threading drives a 23% lift in ACV when it happens before Stage 3.
One is a map. The other is a map with a destination and turn-by-turn directions. You need both, but the market is selling you the map and calling it GPS.
What’s the difference between a predictor and a tracker in sales AI?
This distinction matters more than anything else in this post for a revenue leader evaluating AI tools.
- A tracker — this is what Gong, Chorus, and Attention etc… all build. It monitors signals. Keywords on calls. Talk-to-listen ratios. Email response times. Meeting cadences. It's pattern-recognition. "When reps mention budget in discovery, deals close at a 67% rate." That's a correlation. It's useful for coaching reps. It's not useful for building strategy.
- A predictor — this is what Loop from Fluint builds with discriminant ML. It calculates explanatory weight. It mathematically identifies which variables drive the outcome, how much each one contributes, and how that changes by segment, deal size, or stage. "Budget mention drives a 0.43 outcome weight, but only in enterprise deals over $100K ARR with more than three stakeholders. Below that threshold, it's noise."
What this actually costs you right now: Your enablement leader runs economic buyer training every quarter. Your reps log EB engagement in Salesforce. Gong confirms that deals with EB involvement close at a higher rate. Everyone feels good about it.
Then you run the actual math — discriminant ML against your deal data — and you find out EB identification has a 0.31 predictive weight. It matters, but not nearly as much as everyone assumed. What actually has a 0.92 weight? Multi-threading into the CFO's office. And only 10% of your reps are doing it.
That's the gap between what your team thinks drives revenue and what actually drives revenue. That gap is millions of dollars in misallocated enablement spend, misrouted deals, and playbooks built on vibes instead of math. A tracker can't find it. A predictor can.

4. What ML Models Should Revenue Leaders Understand?
You don't need to build these. You need to understand them well enough to know when a vendor is using real math versus using the word "AI" as a marketing adjective.
Three foundational model types, explained through revenue use cases. No textbook definitions.
Linear and Logistic Regression: The Weight Calculator
- What it does: Takes a bunch of variables — deal size, stakeholder count, stage duration, product line, whatever you're tracking — and calculates how much each one actually contributes to a specific outcome like closed-won or ACV.
- In revenue terms: You have a deal with 15 attributes in Salesforce. Regression tells you stakeholder count contributes 34% of the explanatory weight. Stage 2 duration contributes 22%. Product line contributes 18%. Whether the rep sent a mutual action plan contributes 3%. Now you actually know where to focus instead of guessing.
- What you're doing without it: Guessing. Building playbooks based on what feels right or what worked for your top rep — who might be an outlier, not a template. Spreading enablement budget evenly across behaviors that have wildly uneven impact on outcomes.
- What changes when you have it: You allocate enablement spend based on math. You stop training reps on behaviors that score 0.03 and double down on the ones that score 0.85. You can justify budget to your CFO with numbers instead of stories about what your best rep does differently.
- The thing nobody tells you: Most "AI-powered forecasting" is just regression with a chat interface on top. That's not innovation. That's a wrapper. The math itself is decades old. The value is in what data you train it on and how you deploy the outputs.
Decision Trees and XGBoost: The Deal Router
- What it does: Instead of weighting variables on a line, a decision tree splits your data into branches. "Is ACV above $50K? Yes — go left. Is there a champion? Yes — go left again. Is the CFO engaged? No — go right." Each branch leads to a different probability. XGBoost stacks hundreds of these little trees on top of each other. Each one corrects the mistakes of the last one. It's not one tree making a call. It's an army of trees, each one slightly smarter than the previous one.
- In revenue terms: A new deal enters your pipeline. Instead of one rep's gut feeling, XGBoost runs it through 500 sequential decision trees, each asking a different splitting question, each correcting for what the previous tree got wrong. The output isn't "this deal feels good." It's a predictor score — a number that tells you how much explanatory power a specific variable has over the outcome.
- What you're doing without it: Building one-size-fits-all playbooks. Running pipeline reviews where managers ask the same five questions regardless of deal shape. Treating a $30K two-stakeholder deal the same as a $300K eight-stakeholder deal because your process doesn't know the difference.
- What changes when you have it: Custom predictor scores per variable, per org. You discover that next steps on calls scores 0.15 — basically irrelevant to outcomes — while CFO multi-threading scores 0.92. That's not generic best practice from a sales methodology book. That's your data telling you your truth.
- The thing nobody tells you: This is what makes a predictor fundamentally different from a Gong tracker. A tracker says "this signal showed up in won deals." A predictor built on XGBoost says "this variable, at this branch point, in this segment, after correcting for 500 rounds of error, explains this much of the outcome." One is a single observation. The other is a mathematically validated finding. Same data. Completely different question.
K-Nearest Neighbor (KNN): The Pattern Matcher
- What it does: When a new data point shows up, KNN finds the K closest existing data points across a bunch of dimensions and uses their outcomes to tell you what's probably going to happen.
- In revenue terms: A new deal hits Stage 2. KNN doesn't ask "what does the sales methodology say?" It asks: "Of the 4,000 deals we've seen, which 15 look most like this one across deal size, industry, stakeholder count, stage velocity, product mix, and engagement pattern? What happened to them?"
- If 13 of the 15 closest matches closed-won with an average 62-day cycle time, that's not someone's opinion. That's a structural analog from your own data.
- What you're doing without it: Telling reps "here's what worked before" based on anecdotes from Slack threads and pipeline reviews. Your best manager has great pattern recognition from 15 years of experience. Your newest manager has none. And every time someone leaves, that institutional knowledge walks out with them.
- What changes when you have it: Every deal gets contextualized against its closest historical matches — not based on what a rep remembers, but based on mathematical similarity across dozens of dimensions. Pipeline review stops being "how do you feel about this deal?" and starts being "this deal's three closest analogs all stalled at Stage 3 when the technical evaluation expanded. Has yours?"
- The thing nobody tells you: This is the mathematical foundation behind "what works in situations like this." An LLM has read blog posts and case studies about selling. KNN has the actual outcomes of thousands of deals that structurally resemble the one you're looking at right now. One gives you advice. The other gives you evidence.
5. How Does Token Billing Work and Why Is It a Trap for Sales Teams?
Remember Ten-Second Tom? That forgetting-everything thing has a financial consequence that nobody in the vendor world explains until you get the bill.
What is factorial token billing?
When you send your 15th message in a chat, you're not paying for one message. You're paying for message 15 plus the full history of messages 1 through 14, because the LLM has to re-read the entire conversation to know what's going on.
The cost isn't linear. It's roughly factorial. Message 1 costs 1 unit. Message 2 costs 3 (1+2). Message 3 costs 6 (1+2+3). By message 15, you're somewhere around 120 units — and that's the simplified version. With tool calls, retrieval overhead, and reasoning chains, the real number is worse.
The upgrade trap nobody talks about
When a model provider ships a "smarter" model and says the per-token price hasn't changed, what they don't mention is that the new reasoning architecture burns 30% more tokens per request. Your per-token rate is the same. Your bill went up. They just marketed it as a free upgrade.
It's like your electric company saying they haven't raised rates while installing appliances in your house that draw 30% more power. Technically true. Functionally a price increase.
What this looks like across a real sales team
- What you've probably never done: Calculated your actual cost per chat turn. Audited what gets thrown away during context compaction. Compared the real cost of factorial billing against a flat-fee platform that pre-loads your data. Do the math. It's not close.
- The thing nobody tells you: Adding a new signal to a tracker is basically free — flip a switch, track a new keyword. Adding a new variable to a predictor requires retraining on your data. That retraining costs compute. But the difference between a correlation signal and an explanatory weight is the difference between coaching advice and strategic intelligence. The question is which one you're actually paying for right now.
6. Does a Bigger AI Model Mean Better Results for Sales?
Frontier models — Claude, GPT, whatever comes next — have north of a trillion parameters. A parameter is basically a knob. One of a trillion mathematical adjustments that got tweaked during training.
Think about a cockpit with a trillion dials. Turn one dial and what happens? Nothing you can perceive. The model is so massive and so general that any single adjustment barely registers.
Now think about a purpose-built model with 35 billion parameters. Still a huge cockpit. But now each dial matters way more. A fine-tuning adjustment on a 35B model actually changes what comes out the other end.
Our CTO puts it this way: it's like putting a drop of Kool-Aid in a gallon bucket of water versus putting the same drop in a cup. In the gallon, it disappears. In the cup, you taste it immediately.

How do generalist and purpose-built models compare for revenue teams?

More parameters means more general intelligence. But we've all worked with people who are too smart for their own good — incredibly brilliant, can't actually get anything done. What you want in a revenue model isn't maximum intelligence. It's the sweet spot between smart enough to understand complex deal dynamics and focused enough to actually do something useful with that understanding.
That sweet spot lives somewhere in the 35-60 billion parameter range for sales-specific applications. Purpose-built. Trained on actual deal data. Not a generalist model with a sales skin stretched over the top.
7. What Does a Revenue-Grade AI Architecture Actually Look Like?
Here's what most revenue orgs are running right now:
Notion or Glean for knowledge and context. Gong or Attention for call tracking. Salesforce for the CRM. Some LLM tool bolted on top for chat. Maybe Sibyl for buyer mapping.
Every single layer in that stack introduces opinion. The knowledge base feeds context to an LLM, which gives you probabilistic output. The tracker finds correlations, which a human interprets subjectively. The relationship map shows connections, which get filtered through more probabilistic reasoning.
By the time a rep gets a "recommendation," it's an opinion about an opinion about a pattern about a correlation. That's a game of telephone. And you're calling it strategy.
How does a math-first AI architecture work?

- Step 1 — Raw CRM data in. Every field, timestamp, stakeholder interaction, stage transition. Just data.
- Step 2 — Discriminant ML scores it. XGBoost. Hard math. No opinions. Every variable gets scored against the revenue outcome. CFO attendance = 0.92. Next steps logged = 0.15. Multi-threading depth = 0.78. These aren't guesses. They're mathematically validated weights.
- Step 3 — Small language models rank the actions. Take those scores, determine the top three Next Best Actions. Not based on what an LLM thinks might work. Based on which actions map to the highest-weight predictors that the team is currently under-executing.
- Step 4 — Purpose-built LLM executes the last mile. Draft the email. Write the talk track. Build the multi-threading message. But now it's working from mathematical instructions, not generating opinions from thin air.
- And then it loops. Outcomes feed back into step 1. Every closed deal — won or lost — updates the model. Predictor weights shift as your business changes. The system learns from your actual results, not from internet-scraped generalizations about what selling looks like.
The actual difference
Every vendor in the market (Notion, Glean, Sybill, Attention, etc) is trying to give the LLM more context. Better context. More relevant context. That's fine. That's necessary. But it's not enough.
The LLM in this architecture never scores a deal. Never identifies a predictor. Never decides which action to recommend. All of that happens in discriminant models upstream. The LLM just translates math into language a rep can act on. That's it. That's its job. Last mile execution.
That's the difference between a platform and a wrapper.
The Bottom Line
The AI market for revenue teams is full of wrappers dressed up as platforms. They all sound the same. They all say AI. They all promise to transform your GTM.
The difference is math.
Discriminant models that score deal variables against revenue outcomes. Purpose-built LLMs trained on sales data instead of Reddit. Predictor scores that tell you where to put your resources, not tracker signals that tell you what already happened. Fixed-fee pricing that lets you budget AI like infrastructure instead of hoping your token bill doesn't blow up.
The question isn't whether your revenue team needs AI. It does. The question is whether what you're buying is engineering revenue or just generating expensive opinions.
Now you know how to tell the difference.
FAQ's on:
AI Models for Revenue Teams
AI is the umbrella term for any software that mimics cognitive functions. Machine learning is a specific subset of AI — it's software that learns patterns from data rather than following hardcoded rules. In sales, the distinction matters because most "AI" tools only use LLMs (one narrow type of model), while actual machine learning includes discriminant models like XGBoost and regression that produce factual, deterministic outputs rather than probabilistic opinions.
A tracker (like Gong or Attention) monitors signal frequency and patterns — "this keyword appeared in 67% of won deals." That's a correlation. A predictor (like Loop) uses discriminant ML to calculate the explanatory weight of a variable against a revenue outcome — "this variable explains 43% of the outcome variance in enterprise deals." Trackers are useful for rep coaching. Predictors are useful for GTM strategy, enablement prioritization, and resource allocation.
LLMs hallucinate because the fundamental math was designed to always produce an output. The model is wired to give you an answer even when it doesn't have sufficient context. There are actually two distinct failure modes: fabrication (the model invents information that was never in its context, a model problem) and misapplication (the model uses real data incorrectly, a context problem). For sales teams, this means AI-generated deal summaries, call prep notes, and pipeline analysis can contain errors that reps may not be able to identify.
A generalist LLM (like ChatGPT or Claude) has over a trillion parameters trained on internet-scale data — academic papers, Reddit, pop culture, everything. Fine-tuning it for sales is like adding a drop of flavoring to a gallon of water; it vanishes. A purpose-built sales LLM (like Olli Mesa at ~35 billion parameters) is trained natively on proprietary sales data, meaning every fine-tuning adjustment materially impacts the output. Purpose-built models also tend to offer fixed-fee pricing rather than per-token billing and can be hosted behind a company's IT perimeter for data security.
Token billing charges based on the volume of text processed by the LLM. Because LLMs have no memory, every new chat turn requires re-sending all previous turns — making cost growth roughly factorial, not linear. Your 15th message doesn't cost 15 units; it costs the sum of all preceding messages re-processed. Additionally, when model providers release "smarter" models at the same per-token rate, the new reasoning architecture often consumes 20-40% more tokens per request, effectively raising costs without changing the sticker price.
Seven questions that separate platforms from wrappers: (1) Is your model discriminant or non-discriminant? (2) What happens to my context after 15 chat turns? (3) What's my effective cost at 20 turns vs. a flat fee? (4) Can you show me a predictor score and explain the number? (5) When the model gives bad output, can you tell me if it was fabrication or misapplication? (6) Where does my CRM data go during processing? (7) What specific ML model types are you running? If the vendor can't answer these with technical specifics — model types, training data, parameter counts — they've built a wrapper, not a platform.
Why stop now?
You’re on a roll. Keep reading related write-up’s:



Draft with one click, go from DIY, to done-with-you AI
Get an executive-ready business case in seconds, built with your buyer's words and our AI.
Meet the sellers simplifying complex deals
Loved by top performers from 500+ companies with over $250M in closed-won revenue, across 19,900 deals managed with Fluint

Now getting more call transcripts into the tool so I can do more of that 1-click goodness.



The buying team literally skipped entire steps in the decision process after seeing our champion lay out the value for them.


Which is what Fluint lets me do: enable my champions, by making it easy for them to sell what matters to them and impacts their role.

