What Is GTM Judgment? Why Tacit Knowledge Is the Only Enterprise Sales Moat That Compounds

TL;DR
Most AI sales tools work on explicit knowledge, the stuff you can write down. The real performance gap lives in tacit knowledge, the instincts top reps build over hundreds of cycles and can't explain if you ask them. GTM Judgment is the layer that captures that, wraps it around every deal, and compounds it. Without it, AI in sales is a faster engine pointed nowhere.
What is GTM Judgment?
GTM Judgment is the layer of an AI sales system that captures and applies tacit knowledge. The instincts, pattern recognition, and situational awareness that separate top performers from everyone else on the team.
Any AI can follow a process, but judgment is the thing that tells the system which process applies to this deal, right now, based on what's actually worked in similar situations before. Replicating the “gut take” and instincts top reps use to make nuanced, creative decisions.
Think GPS versus wayfinding: A GPS gives you turn-by-turn (the playbook). Whereas wayfinding figures out a dozen different routes varied by terrain, weather, travel conditions, and knows where the maps are wrong.
What's the difference between tacit and explicit knowledge in sales?
Explicit knowledge is everything you can hand a new AE on day one:
- Playbooks
- Battle cards
- Objection-handling scripts
- Email templates
- Onboarding docs
Searchable, shareable, ingestable by any AI tool. Which is fine.
Tacit knowledge is everything else: the instincts that tell an experienced rep when to push for a next step, and when to let a deal breathe. The pattern recognition that clocks a deal as quietly dying three weeks before it formally stalls. Or the call about which procurement stakeholder to engage before IT gets involved, and why.
By definition, it can't be documented. Your best reps can't explain it. That's the whole point. It gets built from hundreds of closed cycles, absorbed through repetition, and shows up as judgment in the moment.
Explicit knowledge is the framework, tacit knowledge is how you know when to break it.
In almost every enterprise GTM org, about 14% of reps drive 80% of revenue. The explicit stuff is nearly identical across the team:
The gap is almost entirely tacit.
Why can't standard AI sales tools capture tacit knowledge?
Most AI sales tools are LLMs pointed at explicit inputs. A call transcript, a CRM record, recent emails. They're good at that. What they can't do is model the trajectory of a deal over time, and use the motion in-between data points where tacit knowledge actually lives.
An LLM looks at a deal like a photo:
It sees a single frame and generates something plausible about that moment.
Enterprise deals are more like videos. A champion going quiet for 6 days in week 3 of a 90-day cycle means something completely different than the same behavior the week before a renewal. A 7:30pm Friday procurement email from an exec who can't wait to get rolling is a very different signal than the same email waiting until Wednesday morning of the next week, during business hours.
The meaning lives in the sequence, the spacing, and the velocity.
But a prompt-based system can only ever see the current frame. So it can't tell you a deal is dying three weeks before it dies, because it's never watched the other deals die. The output reads reasonably. It's structurally blind to the dimension where the important signals live.
That's why AI sales tools plateau: they're working from a photo when the story is in the film.
What is GTM Drift?
GTM Drift is what happens when tacit knowledge doesn't get captured and compounded: the organization slowly drifts off the path to revenue and doesn't realize it.
It runs at two levels:
- Org Drift. Company-wide. Messaging that used to land stops landing. New hires get trained on what used to work. Nobody notices until the number moves.
- Deal Drift. Individual. A deal that should close starts to wobble. The wrong stakeholder gets looped in. A signal gets missed. A champion goes quiet and nobody catches the pattern. The deal slides sideways. The rep doesn't know why. The manager doesn't know why. The data only shows what happened after the fact.
The only real defense is a system that continuously captures what's actually working, adapts as conditions change, and course-corrects in real time. It's a data and judgment problem. Your sales process can't fix it, neither does better prompting.
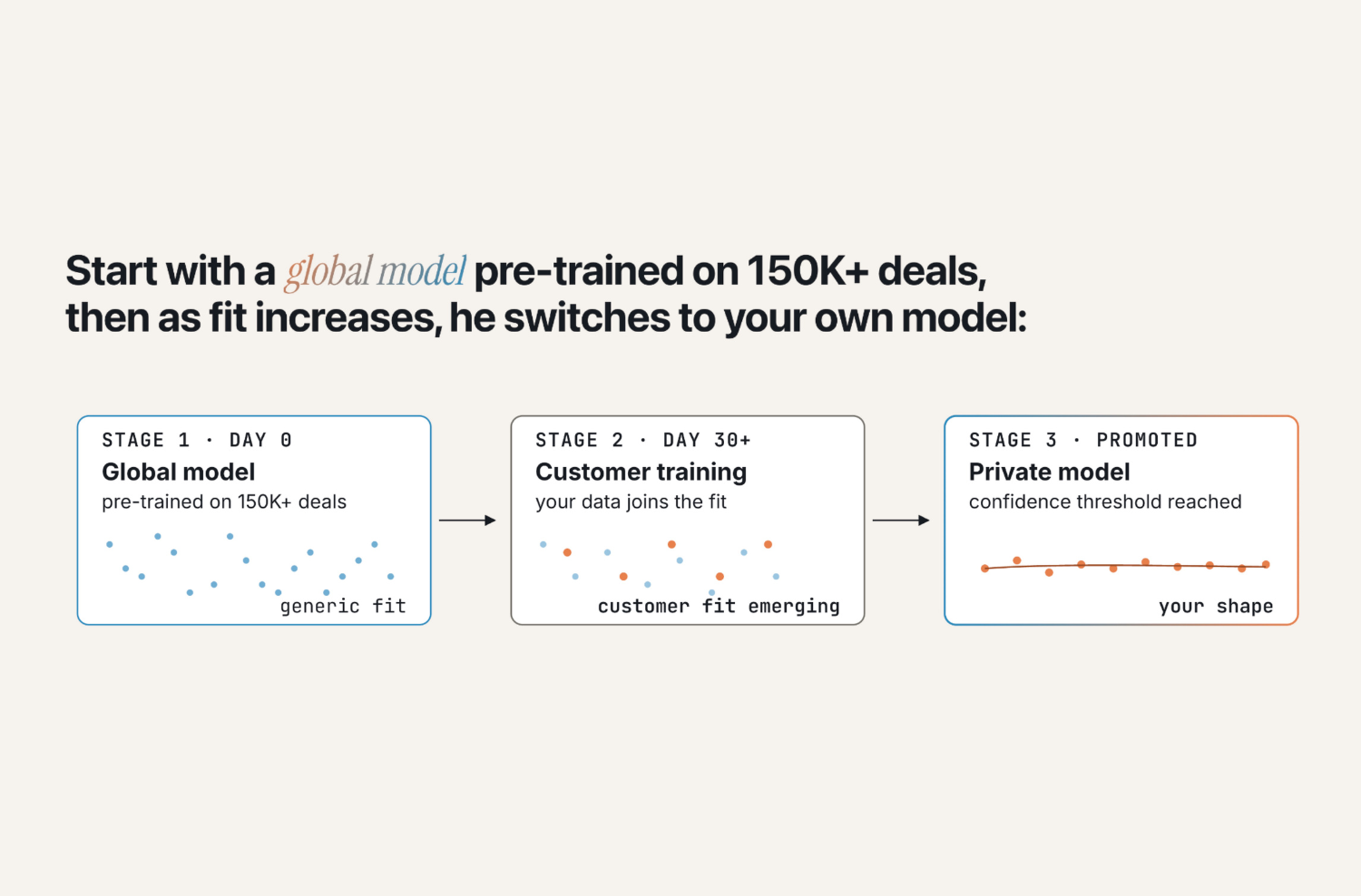
How does GTM Judgment compound over time?
This is where the model separates from a static playbook or a prompt-based AI.
Every deal Olli runs feeds new signals back into the system: what plays got run, which ones the rep adjusted, what the outcome was. That outcome data trains the model's understanding of what actually works for this customer, in this segment, against this buyer profile, at this stage. (General patterns aren't enough.)
The flywheel:
- Olli runs a deal using patterns from 150,000+ comparable cycles
- The rep's adjustments and the deal's outcome become new training data
- The next deal benefits from the updated context
- Over time, the system's judgment reflects the specific patterns of won and lost deals inside your org, not industry-wide trends
A playbook captures explicit knowledge at a point in time. A living judgment layer keeps incorporating the tacit knowledge your team generates every cycle. It sharpens instead of drifting.
What does GTM Judgment look like in practice?
Olli is built on four layers that make this possible:
Every cycle makes the next one sharper. That's the compounding mechanism.
Why is GTM Judgment hard to build in-house?
Three reasons the moat is real.
- The data pipeline is brutally hard. Getting clean, normalized, time-series data out of a full GTM stack (Salesforce, HubSpot, Gong, Outreach, Gmail, Slack, document engagement) and structuring it so a model can actually learn from it is expensive, unglamorous work. We've been building this pipeline for years. A RevOps team standing up agents over a sprint isn't rebuilding it.
- The outcome labels are earned, not bought. The ground truth that makes a deal model useful is what actually happened to the deal, and why. You can't scrape that. You earn it by sitting inside real cycles, watching them resolve, and feeding outcomes back in. Every deal Olli works makes the next prediction sharper.
- “Reproducibility” ends at the data layer. A RevOps team with an LLM and a good prompt can reproduce a snapshot. They can't reproduce a library of 150,000+ enterprise cycles with structured time-series signal and outcome labels. That takes years of product, pipeline, and customer trust. It compounds in a way a prompt strategy never will.
Why we built Olli around GTM Judgment
I've spent a lot of time inside enterprise GTM teams over the past few years. The same problem kept showing up regardless of company size, tech stack, or how sophisticated the team was.
The gap between top performers and everyone else wasn't the process. The people who'd been in the trenches long enough had built a kind of situational intelligence about buyers, about deal trajectories, about when to push and when to back off, and it couldn't be transferred. It lived in them. When they left, it left too.
Nobody had built a system to capture it.
Most AI tools we looked at were solving the execution problem. Faster content, better templates, automated follow-up. Useful. But they were making the engine faster without knowing where to point it. We kept watching teams with great AI tooling lose deals they should have won, because the judgment layer was missing. The layer that knows which play to run, for this deal, right now, based on what's actually worked before.
That's what Olli is built to do. Wrap the judgment of your best reps around every deal in the pipeline, and compound it with every cycle that runs.
Go deeper
Read the internal memo → The strategic brief we shared with our team on GTM Judgment. Where AI in enterprise sales has missed, and what it needs to do instead. We leaked it. Worth 10 minutes.
The technical guide: build vs. buy → Fluint CTO Jon Crawley's full breakdown of the five systems required to build a judgment layer in-house. Time-series data architecture, tacit knowledge capture, deal scoring, the rest. Required reading if your RevOps or engineering team is evaluating this internally.
See Olli in action → If you want to see how the judgment layer works inside a live enterprise sales motion, we're happy to show you.
FAQ's on:
A playbook captures explicit knowledge: documented processes and best practices at a point in time. GTM Judgment captures tacit knowledge: the instincts, pattern recognition, and situational awareness top reps develop over hundreds of cycles and can't articulate. A playbook tells you what to do. GTM Judgment tells you what to do in this situation, based on what's actually worked in comparable ones.
No. LLMs operate on a single frame of context. They're stateless by design and can't model the trajectory of a deal over time. GTM Judgment requires ML trained on time-series outcome data: the sequence, velocity, and spacing of deal signals mapped against won and lost results. An LLM alone generates plausible outputs from a snapshot. It can't tell you a deal is dying three weeks before it dies.
Explicit knowledge is everything that can be documented: playbooks, scripts, battle cards, onboarding materials. Tacit knowledge is the judgment that can't be written down: the pattern recognition and situational instinct top reps build through experience. Explicit knowledge is teachable. Tacit knowledge has to be observed, modeled, and encoded at the behavioral level.
Tacit knowledge that never got captured. The org slowly diverges from the patterns that actually drive revenue. Org Drift is the company-wide version: messaging that used to work stops working, new hires get trained on outdated patterns, nobody notices until revenue drops. Deal Drift is the individual version: a deal wobbles because the wrong signal got missed or the wrong stakeholder got engaged, and the rep doesn't have the pattern recognition to catch it in time.
Most AI sales tools operate on explicit inputs (transcripts, CRM records, emails) and generate outputs from that snapshot. Olli's judgment layer models the trajectory of a deal over time using ML trained on 150,000+ comparable cycles plus each customer's own won/loss data. The difference is between an AI that reads what's happening now and one that knows what this deal trajectory has historically led to
Why stop now?
You’re on a roll. Keep reading related write-up’s:


.webp)
Draft with one click, go from DIY, to done-with-you AI
Get an executive-ready business case in seconds, built with your buyer's words and our AI.
Meet the sellers simplifying complex deals
Loved by top performers from 500+ companies with over $250M in closed-won revenue, across 19,900 deals managed with Fluint

Now getting more call transcripts into the tool so I can do more of that 1-click goodness.



The buying team literally skipped entire steps in the decision process after seeing our champion lay out the value for them.


Which is what Fluint lets me do: enable my champions, by making it easy for them to sell what matters to them and impacts their role.

